

Have you ever wondered how computers learn to play games like Chess or Go? Or how do they replace human players in Ludo or Card games? How Google's Alpha-Go defeated the World Champion of Go? Let us dive in the field of Computer Games and find out how Computers learn to play Games!

There are various algorithms that are used to make a computer learn to play games. I will be discussing some of them to give you some intuition on how these algorithms work.
Let's start with a simple and naive approach by which the computer can take decisions. It is by looking at all possible states and choosing the best action to take. That is, make a tree with all possible states and next states and go to the leaves to find out if a move will lead to winning state or not and select an action accordingly.
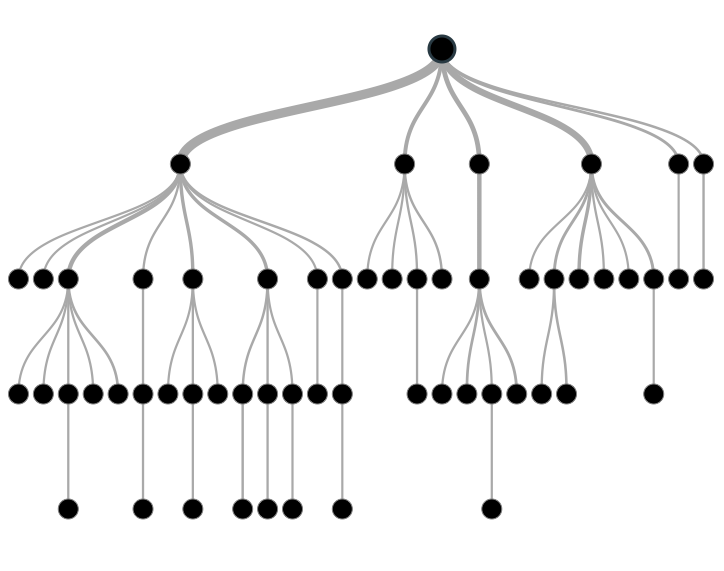
But, this technique cannot be used for games where there is a huge number of states, that it is practically impossible for a computer to examine all the states before taking a decision. For example, there are more than 5000 states in the game of Tic-Tac-Toe, which is a 3 X 3 board game. Whereas Chess is an 8 X 8 board game and Go can have a 19 X 19 board. Therefore these games with billions of states cannot be solved by any such brute force approach where examining each state is required.
Monte-Carlo Tree Search can be only used for games where we have perfect information about the game that is we know about all the actions that were previously taken and can be taken in future. It is applicable to games like Go, Chess or Tic-Tac-Toe. So, what the computer does in Monte Carlo Tree Search is it repeats these 4 steps
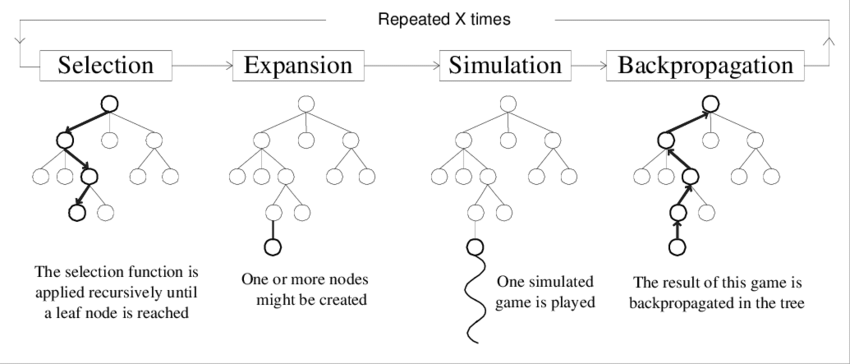
In this step the computer starts with a root node(state) and selects the next node based on the current policy. A policy is a function that dictates what actions to take given a state.
When the policy can no longer choose an action with confidence to find the successor node, it expands the game tree by appending all possible states from that node or a few let's say 10 or 100 states chosen by randomly trying out certain number of actions, this is done when the number of next possible states is huge.
Then from the appended nodes, it simulates a random game to find out how good it is to go to that state.
Then it traverses upwards back to the root and updates the score for all visited nodes.
These four steps are repeated again and again until the computer has learned enough to actually play the game.
There are various algorithms that come under Reinforcement Learning Algorithms. Each suitable for a different purpose. The basic idea behind Reinforcement Learning is, as the name suggests, making the computer play the game again and again and learn from its own experience. In order to give you intuition on how Reinforcement Learning can be used for games with a huge state space let me define two new terms.
1. State Value Function - Given a state this function tells how good it is to be in that state.
2. Action Value Function - Given an action and a state, this function tells how good it is to take that action from the given state.
The basic idea is to learn the value functions and use it to choose the best action. Consider the following diagram-
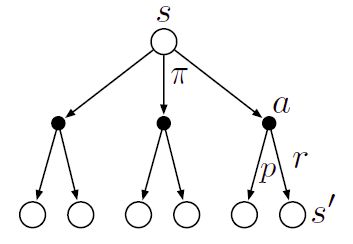
What the computer does is from a given state it chooses the best action based on the action value function and proceeds, and depending upon what reward it gets, the computer modifies the action value function accordingly (This Reinforcement Learning Technique is called Q-learning, have a look at the following blog post to get a better understanding of how this algorithm works.).
The answer is the computer is not really going through all the possible states but still learning an approximate way to figure out the best actions to take. There are many states in the state-space which occur very rarely or is too poor to begin with, that there is no point going all the way down from that state and calculating everything when there are very fewer chances of encountering that state or there is no way it can get you a better reward. But as our computer plays multiple games it will surely go through most of the frequently occurring and promising states and will know how to behave in those situations.
Recently Google's Alpha-Go zero defeated Go's World Champion Lee Sedol. Alpha Go Zero learned to play Go from scratch by playing multiple games against itself. In Alpha-Go deep learning and Monte Carlo Tree Search were combined to produce a powerful reinforcement learning algorithm.

If you are wondering why it is so much of a big deal because AI has already defeated Chess Grandmaster Garry Kasparov in the game of chess then why not Lee Sedol in Go! There are various differences between Chess and Go, and that is why it took another 20 years after Garry Kasparov's defeat to build an AI which can master Go. One of the major differences is the number of choices available at each step, which is about 35 in Chess compared to 250 in Go. Also, the number of moves per game, Go might last for 150 moves vs. 80 in chess. Therefore the total number of possible games of Go has been estimated at 10^761, compared to 10^120 for chess which is a huge difference. That's why it has been difficult for computers to master Go.
I hope you enjoyed this dive into the World of computer games and got to know some of the technical details too. You can go through the following links to know more about these topics.