

According to Wikipedia, the term "software multitenancy" refers to a software architecture in which a single instance of software runs on a server and serves multiple tenants. With a multitenant architecture, a software application is designed to provide every tenant a dedicated share of the resources.
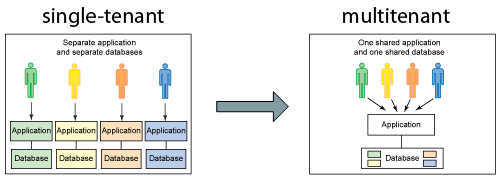
The initial aim of a multitenant architecture was to optimise resource allocation in an application. Instead of providing multiple instances of the same software, a single instance of the software was used to serve multiple tenants. But times have changed. Today, 15 years or more after the creation of application and database multi-tenancy, things are different; the economic necessity for multi-tenancy at the application tier has disappeared. We have huge clouds offering cheap infrastructure and tools creating new instances and tearing them down again without any of the manual interventions that used to be necessary.
Trust, or the lack thereof, is the number one factor blocking the adoption of Software as a Service (SaaS). SaaS applications provide customers with centralized, network-based access to data with less overhead than is possible when using a locally-installed application. But in order to take advantage of the benefits of SaaS, an organization must surrender a level of control over its own data, trusting the SaaS vendor to keep it safe and away from prying eyes. To earn this trust, one of the highest priorities for a prospective SaaS architect is creating a SaaS data architecture that is both robust and secure enough to satisfy tenants or clients who are concerned about surrendering control of vital business data to a third party, while also being efficient and cost-effective to administer and maintain.

In Multi-tenant applications, one instance serves more than one organization, but at the same time provides virtual isolation to data and applications from other tenants of the application. Multitenancy is applied to data, operating system and even hardware. But in this article we talk only about data.
We live in the world of artificial intelligence and machine learning. Every application and website has some form of intelligence incorporated into it. But the learning curve of the machine learning models depend on the data provided by the user. Do you see how multitenancy gets applied here? Let me explain with a scenario. You have deployed a website which provides description of an image that you upload. Like you see in many cognitive services, if you put a picture of a guy trekking, it will say " A picture of a guy trekking". The training model is trained with some data which you had collected. But since you have deployed and people are using the, you decide you can improve the model by retraining the model with the new pictures and also correct the model based on the feedback of the results that you provide. Sounds good right, you have a cool website which learns on its own through time. But there is one problem. What if one day, a user mails you asking whether the pictures he upload are private and are not shared. You say that they are private and cannot be accessed by anyone. He decides to check it out by uploading an image from his own account. He gave a feedback regarding the prediction. Then he creates a new account and tries with the same picture. He gets the updated result, ie. the result considering his feedback. This makes him feel insecure about using your website. This is the trust issue that we talked about earlier.
In the case of SaaS applications, the application vendor does not own the customer data. So it cannot use one customers data to train a model which is used by other customers. To tackle this issue, we need an architecture which does not use one user's data to retrain a model which is used by other users. This virtual isolation is provided by a multitenant architecture. The simple way to tackle this problem is by creating a new model for each tenant. Whenever a new user signs up, create a new instance for that user with the basic training done in the mode. All further predictions and retraining for that user will be done to the model exclusive to him. This ensures data isolation while model retraining. The disadvantage of this is memory. A separate model for every user consumes a lot of memory. The other approach is to intelligently share the models among some users. Instead of creating a new model for each user, only create an instant of the model. All retraining can be done to this instant. The instant can be destroyed and put away to secondary memory when the user is inactive. Though the second method has a lot of overhead, because of the memory it saves, this is method is preferred. You might be confuse thinking how creating new instances of models support multitenancy. Isn't this the opposite of multitenancy. No, this is because we are still using only one instance of the application. Only the machine learning model that it accesses varies.
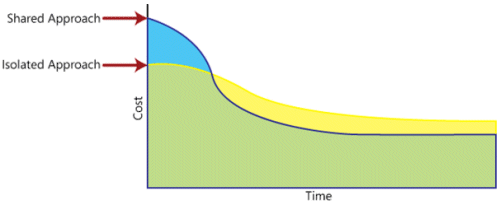
Factors influencing 1. Economic considerations 2. Security considerations 3. Tenant considerations 4. Law and order considerations 5. Complexity considerations