

I am pretty sure the title will flood the reader’s mind with images of Skynet and Matrix, but this post focuses on the shortcomings of AI technologies that are currently in vogue. It’s much more productive to contemplate on the loopholes in technologies like Neural Networks, as we are still a far cry from building systems that are at least as intelligent as earthworms.
AI has made several inroads into diverse fields such as NLP, Computer Vision, Autonomous Vehicles, Personal Assistants, and Game playing bots. AI has become truly ubiquitous. This magnifies the impact of security loopholes on the society. Accidents, in the context of AI, are defined as unintended or unexpected actions of the system, that might be harmful to human beings, and might cause irreversible damage to the environment. These may be caused due to reasons like incorrect objective function, errors in the implementation or the systems not being robust to outlier inputs. Many of ML problems are solved by designing algorithms that optimise a particular function - this function is known as the objective function. An objective function can be specified either as a cost functions(that gives us the error in the predictions, and hence has to be minimised) or as utility function(used to specify rewards for Reinforcement Learning agents, which try to maximise this reward). Another reason, that augments research in this area is that, the Value Alignment problem shares a major intersection of ideas with the security concerns.
So what exactly is the Value Alignment problem? Suppose that our system consists of n variables, and we define our objective / utility function in terms of k variables, where k is a subset of n. So, there are chances of the system optimising the utility function by setting the other variables to extreme values. This might cause a lot of permanent damage. Suppose we design genuine AGI(Artificial General Intelligence) for getting us medicines. Now, we wouldn't want it to imfringe upon others' rights when we want it to get medicines in the most optimal way right? Like, it shouldn't break the trafffic rules, it should stand in a queue, it must not steal the medicines,etc. The paperclip maximiser is a funny, but instructive example that demonstrates this problem.
Most of the alignment problems initially show up as security issues itself. The value alignment problem isn’t born out of the spooky fears of evil-intent and consciousness arising out of super-intelligent machines, but because of the following reasons:
Let’s explore some of the ways in which AI systems can malfunction:
We are quite familiar with Sorcerer’s Apprentice or King Midas’ story - “We all get what we ask for, not what we want”. For instance, consider the case when google photos tagged a person as Gorrilla - Google apologises for Photos app's racist blunder This was not because the AI system wanted to hurt the sentiments of particular section of society. It might be because, the cost function for misclassification of inanimate objects is the same as that of misclassifying people as animals/objects. On the contrary, greater cost should have been associated with misclassification of humans. This illustrates the unintended effects of faulty reward functions.
The AI system may try to maximise its reward function, without heeding to the other environment variables. For instance, consider the example of a robot used to clean office spaces: The robot must not break an expensive vase in it’s way, and must search for an alternative path, although the cleaning process might be faster in the former approach.
The system may find out a clever/easy way of increasing the reward, but might be against the spirit with which it was designed. Continuing with the same analogy, the robot might purposefully shut it’s vision system so that it cannot ‘see’ any dirt, or it might hide the existing dirt with objects, so that the dirt is not visible to others. Take a look at this AI bot, that’s designed to play the speedboat game of CoastRunners. Here, the boat that finishes first gets the maximum points. So, when this RL agent was given reward function of obtaining maximum points, it does not participate in the race, but rather tries to obtain higher points by perfecting it’s timing of going around in the circle as shown. Indeed, the number of points obtained by the bot was 20% higher than an average human player, but this was not what the designer had in her mind. More on this by OpenAI - Faulty Reward Functions
Hence many attempts have been made at evaluating a system’s performance and solving the “reward engineering problem”. For instance consider, Cooperative Inverse Reinforcement Learning(CIRL) - here, a robot observes a human being in an open environment and ‘infers’ the reward function by itself, rather than being explicitly specified. This is a paper on CIRL from researchers at BAIR - Cooperative Inverse Reinforcement Learning . OpenAI has also released Universe, which makes it easier to compare a machine’s performance in a game with that of a human being.
As the name suggests, we are trying to create inputs that bypass an ML algorithm. This is probably one of the segments that is receiving a lot of focus in the recent years. Neural Networks have been immensely popular for computer vision tasks, but of late they have been prone to a lot of adversarial loopholes. Initially, a ML algorithm will have correctly classified an input. But a very slight perturbation is added to the original input, which is so subtle that it is nearly imperceptible to humans, but this often “fools” the classifier and results in an incorrect output. Consider this,
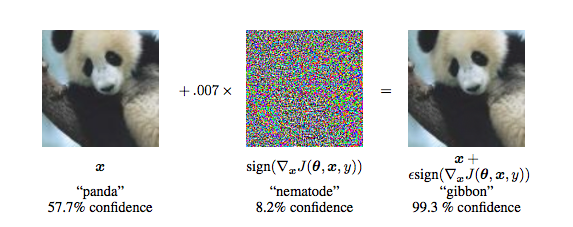
On the LHS, the image is classified as a panda with 57% confidence. Although the middle image appears as random noise, it’s obtained by maximising the prediction error of the classifier, but this surprisingly results in the wrong classification as a “gibbon”. As we can observe, the difference between RHS and LHS images is quite imperceptible. It is true that, an attacker may not have access to directly input data into a classifier, so experiments were done to take input from camera devices, but similar results were obtained. Epsilon refers to the extent of perturbation added. In the below image, the image classifier is fooled into classifying the washing machine as a safe (34% probability) and as a loudspeaker(24% probability).

Further, it was believed that since Autonomous vehicles take many pictures from varied angles, perspectives and scales they would not be deceived very easily. But researchers were able to generate scale-invariant and transformation-invariant adversarial inputs also - Synthesizing Robust Adversarial Examples. Scale invariance implies, even if all the dimensions of input are multiplied by a common factor, the output is still misclassified. Similarly, the results won't change much, even if tranforms(like geometric/morphological transforms) are applied onto these images. Hence, Adversarial Examples is one of the critical research areas in ML Security. The cleverhans library is used to benchmark and evaluate the vulnerability of ML models against adversarial inputs.
I think that Safety of ML models is a very exciting and crucial area in the coming years. It is quintessential to resolve these issues for the realization of products like Autonomous Driving Vehicles and Personal Robots. As AI systems make deeper inroads into our lives, ensuring the safety and reliability of these systems is of paramount importance. Please do put in your comments/suggestions regarding this article below.