

It’s manually impossible to understand the structure of a dataset with 100 dimensions. And it’s fairly common to come across data having so many features. And the exploratory-analysis of data is a preliminary step, before proceeding to other aspects of data-wrangling and models. This is where t-SNE comes in.
t-SNE is non-linear dimensionality reduction algorithm. It reduces each high-dimensional point and embeds them into a 2D/3D map. Additionally, it ensures that similar objects are nearby and dissimilar points are kept apart.
Here's a nice example of t-SNE's usage in last year's IEEE project(GoT chabot) https://gist.github.com/kaushiksk/ea0c0f25c082acb8604ad84466f85ca8
It’s necessary to know about other dimensionality reduction techniques like Principal Component Analysis (PCA) to truly appreciate the distinctive nature of t-SNE.
PCA tries to retain the maximum information about high-dimensional data even after embedding it into a low dimension. It does this by finding out a few components in the higher dimension along which the maximum variation of the data is ensured. Hence it preserves the variation in the data even after reducing it to a lower dimension. Mathematically, PCA minimises the squared-error between points - essentially ensures that far-away points in the original dataset remain in the same way in the 2D map also. So PCA preserves large pairwise distances(global structure and properties), but these distances do not imply any meaningful property. But it loses the the low-variance deviations between neighbours. t-SNE filled this gap by accounting for local properties, which have a lot of significance irrespective of the overall structure/topology of data.
Moreover PCA is not very useful for unlabelled data. This is quite evident by looking at the visualizations produced by PCA and t-SNE on the MNIST dataset.
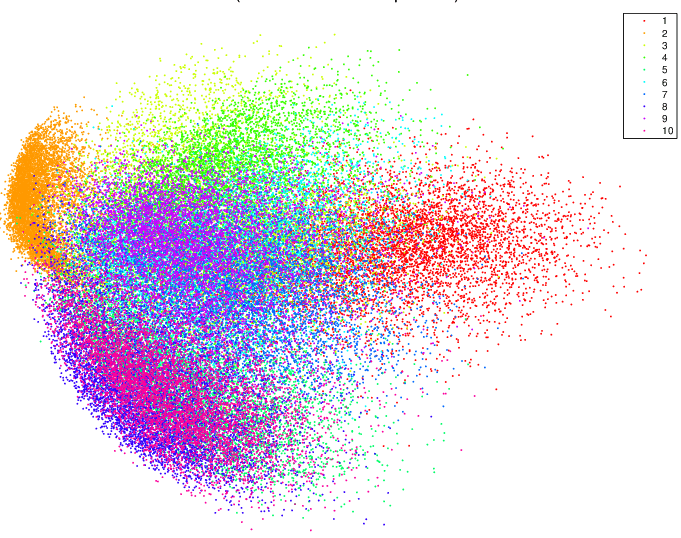
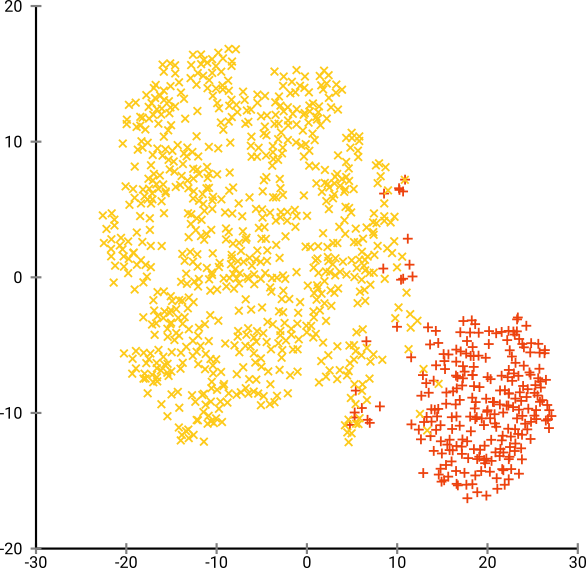
Distinct clusters are not produced by PCA. The distinctness is evident only because of the color-coding, so PCA is not very helpful for unlabelled data.

On the other hand, the presence of clusters is striking with unlabelled-data using t-SNE. The bottom right, we can see the labelled version of the same. Hence, t-SNE finds a lot of utility with unlabelled data, over and above PCA.
Some Interesting properties of t-SNE:
So the effectiveness/relevance of t-SNE is put into question if the required output is in a fairly higher dimension, where the possibility of crowding is low. On the other hand, PCA always gives the best components along which the variance of the data is maximised.
Hence, the results of t-SNE is much better if the degrees of freedom is increased, because the crowding problem is less severe. Consequently, visualising data in 3D rather than 2D gives a lot of gains in using t-SNE.
Do not apply clustering upon the output of t-SNE
Multiple runs with the same parameters might not give the same result
Perplexity is one of the parameters required by the algorithm. It dictates the number of effective of neighbours to be considered while calculating probabilities. So, the perplexity of a distribution over N items can never be higher than N (in this case, the distribution will be uniform). At low values of perplexity, the local variations might dominate, so usually values between 5 and 50 are chosen. We don't have a universal value of ideal perplexity that gives the best results for all types of datasets, so we will have to tune it as a hyper parameter. With increase in number and density of data points, perplexity should also increase.
t-SNE can generate fake patterns at suboptimal perplexities. We may be on a wild-goose chase if we incorrectly expect clusters when there are actually none.
Consider a gaussian distribution with 250 points in (-2, 0) and 500 points in (0, 2).
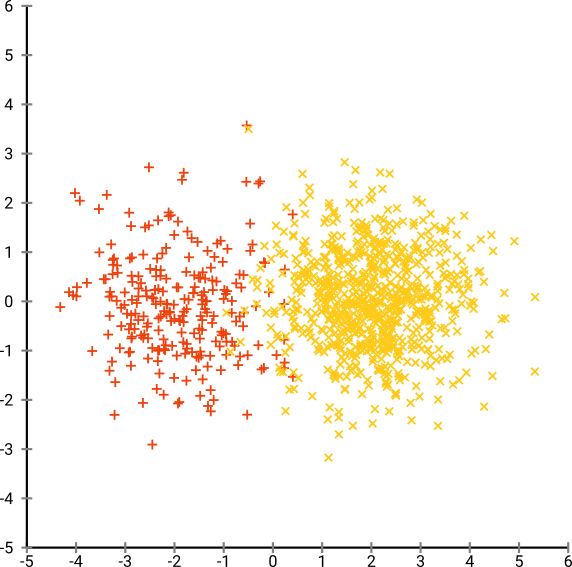
Using EM(Expectation Maximisation) clustering algorithm produces this result:
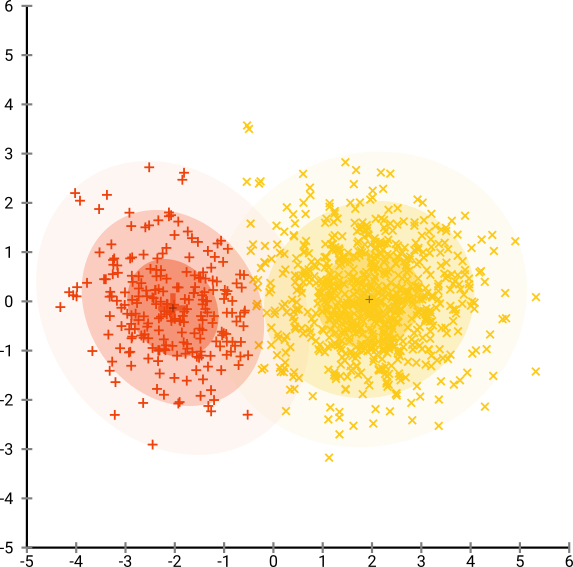
The following are the visualizations produced by t-SNE:
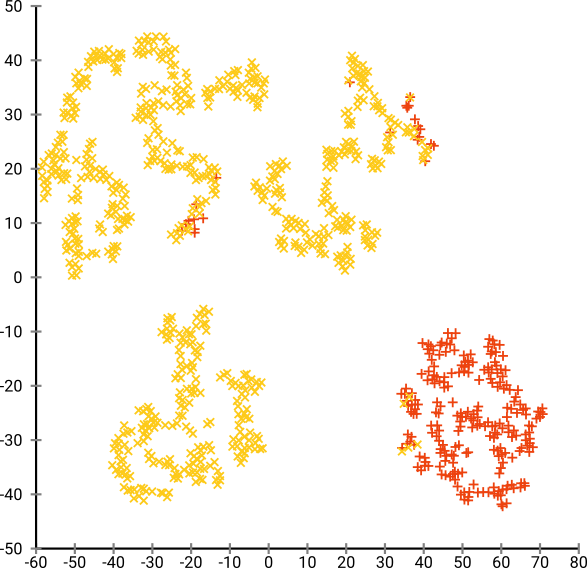
It’s easy to conclude that there are 4 clusters here, while there are only two.
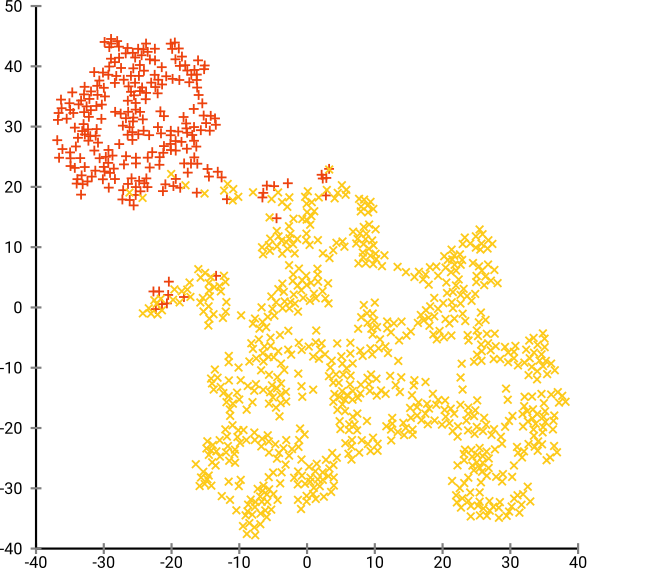
Here, there are too many clusters, and it’s hard for any dim-reduction algorithm to find them. (Note: The color coding is only for our interpretation)
This result is from the optimum perplexity of 80, but since perplexity is a global parameter that needs to be tuned and is not the same for every dataset.
The results are even more stark when these visualizations are obtained from a gaussian distribution as illustrated here. (https://distill.pub/2016/misread-tsne/)
But later implementations of t-SNE have better time complexity
There are certain cases t-SNE could be sub-optimal:
Interpretability: t-SNE only maps the local l variables correctly, and the global trends in the data isn't accurately represented. But PCA's results can be explained very easily.
Application to new data: t-SNE learns a non-parametric mapping - it does not learn an explicit function from the input space to the map. The embedding in t-SNE is learnt by directly moving the data from high-dimension to low dimension. So we can't apply t-SNE on the fly for an incoming test data point. But we can always apply t-SNE on the whole dataset again. Alternately, we can train a multivariable regressor to predict the position of an input point in the map or directly minimise the t-SNE loss (https://lvdmaaten.github.io/publications/papers/AISTATS_2009.pdf).
Incomplete Data: t-SNE cannot handle incomplete data. A popular workaround is to use probabilistic PCA on the data, and then use t-SNE.
Further Reading: 1. t-SNE 2. Visualizing Representations: Deep Learning and Human Beings Christopher Olah's blog, 2015 3. https://distill.pub/2016/misread-tsne/ 4. Visualizing Data Using t-SNE
Despite these misgivings, t-SNE might probably be the first tool a data scientist uses in the morning! Have fun exploring it. Do comment below for any clarifications or suggestions.