

Smart Construction Resource Monitoring & Forecasting Platform using BIM– IoT–ML Integration
Abstract
Abstract
I. INTRODUCTION
A. Background of the Study
The global construction sector is a multi-trillion-dollar industry characterized by immense complexity. It involves the coordination of vast capital, heavy machinery, diverse human labour, and continuous supply chains. However, despite rapid advancements in civil engineering, project management methodologies remain largely archaic. Site engineers and project managers often rely on static spreadsheets, localized observations, and disconnected software systems to track daily progress.
B. The Problem Statement
Construction projects predominantly fail to meet their deadlines and budgets due to the lack of real-time monitoring and predictive intelligence. Traditional systems are reactive rather than proactive; a supply shortage or a weather-induced delay is often only addressed after it has halted construction. Furthermore, architectural planning (BIM) and on-site execution (IoT/Manual Tracking) are treated as isolated silos. There is currently no robust, integrated framework that combines structural requirements with real-time site variables to predict what will happen next.
C. Proposed Solution and Objectives
This project introduces a data-driven solution designed to break down these silos by unifying three core technologies:
1. BIM (Building Information Modelling): To provide the static, foundational truth of the project (e.g., exact volumes of concrete and steel required per floor).
2. IoT (Internet of Things) Simulation: To inject the dynamic, unpredictable nature of a real site (e.g., heavy rain, worker absenteeism).
3. Machine Learning (ML): To act as the brain of the platform, analysing the intersection of BIM constraints and IoT variables to predict resource usage.
Specific Objectives:
To design a 3D structural model and extract precise material quantities using Revit.
To computationally simulate 150 days of realistic, multi-variable IoT data reflecting on-site conditions.
To preprocess and merge these disparate datasets into a unified machinelearning pipeline.
To train, validate, and compare tree-based ensemble models (Random Forest, XGBoost, LightGBM) for predicting daily concrete and resource usage.
To deploy a user-centric web platform via Streamlit that visualizes 7-day future resource forecasts for site managers.
II. LITERATURE REVIEW
A thorough investigation of current literature reveals a significant transition toward "Construction 4.0", the digitization of the built environment.
1. The Role of BIM in Modern Construction: Recent studies (e.g., Sacks et al., 2018) emphasize that BIM has successfully transitioned the industry from 2D CAD to 3D parametric modelling. BIM provides excellent visualization and accurate initial Quantity Take-Offs (QTO). However, literature notes a major limitation: BIM models are static. Once construction begins, the BIM model rarely updates in real-time to reflect actual daily progress.
2. IoT for On-Site Monitoring: Research into IoT applications highlights the use of RFID tags for material tracking and DHT sensors for environmental monitoring. While these studies prove that real-time data collection improves productivity, the data is typically only used for historical dashboards.
3. The Research Gap: The major gap identified in the existing literature is the lack of predictive integration. While some researchers integrate BIM and IoT, they fail to apply complex Machine Learning to forecast future states. This project directly addresses this void. By feeding simulated IoT data and BIM structural data into XGBoost and LightGBM models, this project shifts the paradigm from simple monitoring to predictive construction planning.
III. TECHNOLOGIES AND THEORETICAL FRAMEWORK
A. Building Information Modelling (BIM) via Autodesk Revit
In the context of modern construction, Autodesk Revit is utilized not merely as a 3D drafting tool, but as a comprehensive, parametric relational database. Traditional 2D CAD provides purely geometric representations, whereas BIM operates on objectoriented architecture. Every structural element whether a retaining wall, load-bearing column, or concrete slab, is instantiated as a data-rich object containing embedded metadata. This metadata encompasses physical dimensions, material grades (e.g., M25 concrete, Fe500 steel), structural load capacities, and construction phasing. For this project, Revit acts as the "ground truth" generator. By leveraging Revit’s Level of Development (LOD) standards, precise material volumetric data and Quantity Take- Offs (QTO) are extracted. This forms the static baseline dataset, representing the ideal target timeline and material requirements before external variables are introduced.
B. Advanced Machine Learning Algorithms
Construction sites are highly stochastic environments. The relationship between independent variables (e.g., ambient temperature, workforce availability, equipment breakdown) and the dependent variable (daily concrete poured) is inherently nonlinear and multidimensional. Consequently, traditional linear regression models are severely inadequate. To capture these complex interactions, this project implements advanced Tree-Based Ensemble Learning frameworks:
1. Random Forest: Operating on the principle of Bootstrap Aggregating (Bagging), this algorithm constructs a multitude of independent decision trees during the training phase. Each tree is trained on a random subset of the data and a random subset of features. The final output is determined by averaging the predictions (for regression tasks). This built-in randomness makes Random Forest exceptionally robust against overfitting, allowing it to act as a highly stable baseline model capable of handling the noise present in simulated site data.
2. XGBoost (Extreme Gradient Boosting): XGBoost is an optimized, distributed gradient boosting library designed for high efficiency and flexibility. Unlike Random Forest, which builds trees independently, XGBoost builds trees sequentially. Each new tree is specifically optimized to correct the residual errors of the preceding trees using gradient descent algorithms. Furthermore, XGBoost incorporates L1 (Lasso) and L2 (Ridge) regularization to penalize overly complex models, ensuring high predictive accuracy without sacrificing generalizability.
3. LightGBM (Light Gradient Boosting Machine): Developed by Microsoft, LightGBM is engineered for maximum computational speed and memory efficiency. While traditional algorithms grow trees "level-wise" (depth-first), LightGBM utilizes a "leaf-wise" growth strategy, choosing to expand the leaf that yields the maximum decrease in loss. By employing techniques like Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB), LightGBM processes large datasets rapidly, making it the ideal candidate for future integration with high-frequency live IoT sensor streams.
C. Web Deployment via Streamlit
Bridging the gap between complex backend machine learning computation and enduser accessibility is critical for real-world application. Streamlit, an open-source Python framework, was selected over traditional web frameworks (like Django or Flask) due to its specialized design for data science and machine learning applications. It allows for the rapid development of an interactive Graphical User Interface (GUI) that inherently understands Pandas DataFrames and Scikit-Learn models. Streamlit processes user inputs iteratively, meaning that when a site engineer adjusts a slider for "Expected Rain," the entire backend ML pipeline is instantly re-triggered, updating the forecast visualizations in real-time without requiring manual page reloads.
IV. METHODOLOGY AND EXPERIMENTAL SETUP
The experimental methodology is systematically architected to ensure a seamless high-fidelity data pipeline, flowing from static structural design parameters, through dynamic stochastic data simulation, into rigorous predictive modelling.
Step 1: BIM Data Extraction and Structuring
The workflow initiated with the creation of a comprehensive, multi-story structural model in Autodesk Revit, developed to a Level of Development (LOD) 300 standard. Operating as an object-oriented parametric database, Revit categorizes the structure into logical, hierarchical families (Foundations Columns Beams Slabs).
Using Revit’s native "Schedules/Quantities" functionality, specific structural elements were isolated. The software dynamically computed exact spatial geometries, translating 3D coordinates into precise material volumes, specifically concrete (m3) and the requisite tonnage of reinforcing steel per floor and per structural phase. This tabulated metadata was seamlessly exported into a structured CSV format, serving as the definitive "target goal" or dependent variable matrix (y) for the construction timeline. This establishes the theoretical baseline before external, real-world entropy is introduced.
REVIT MODEL
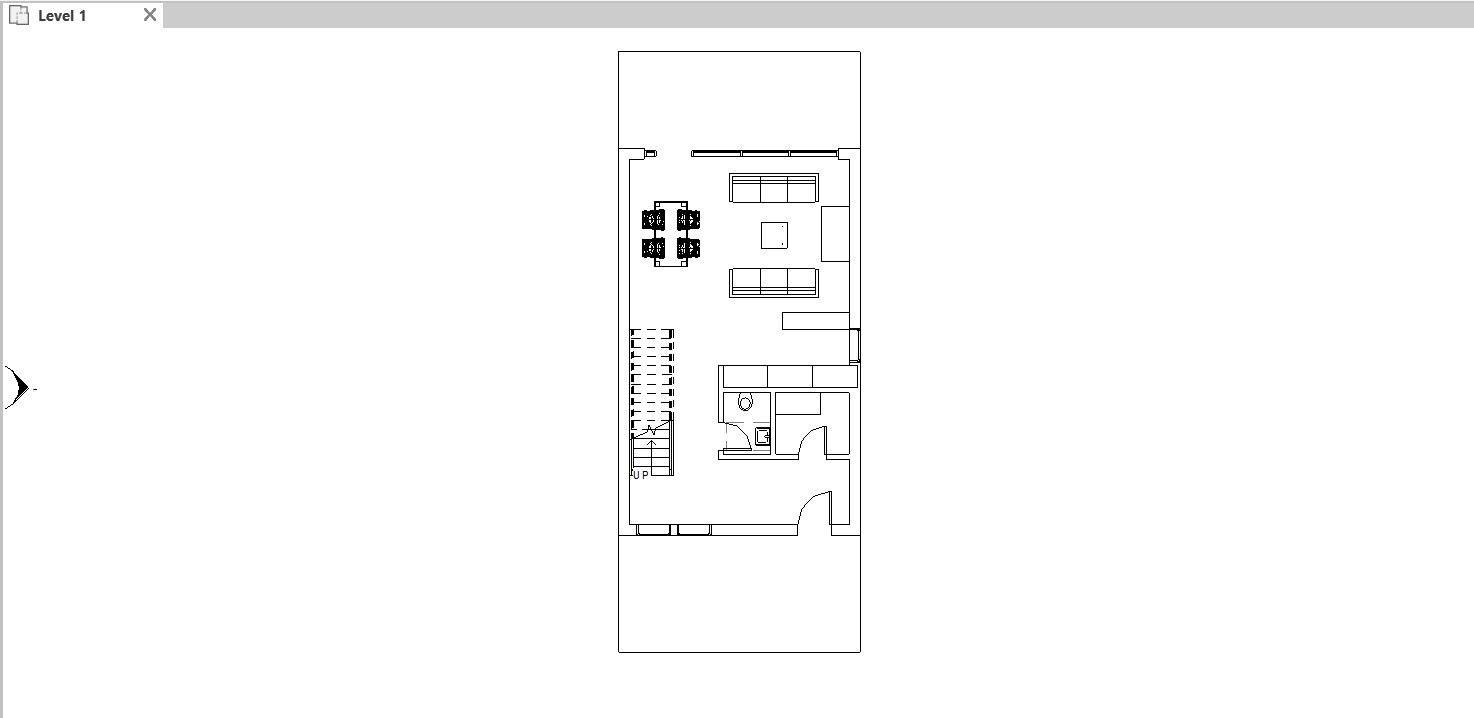
LEVEL 1
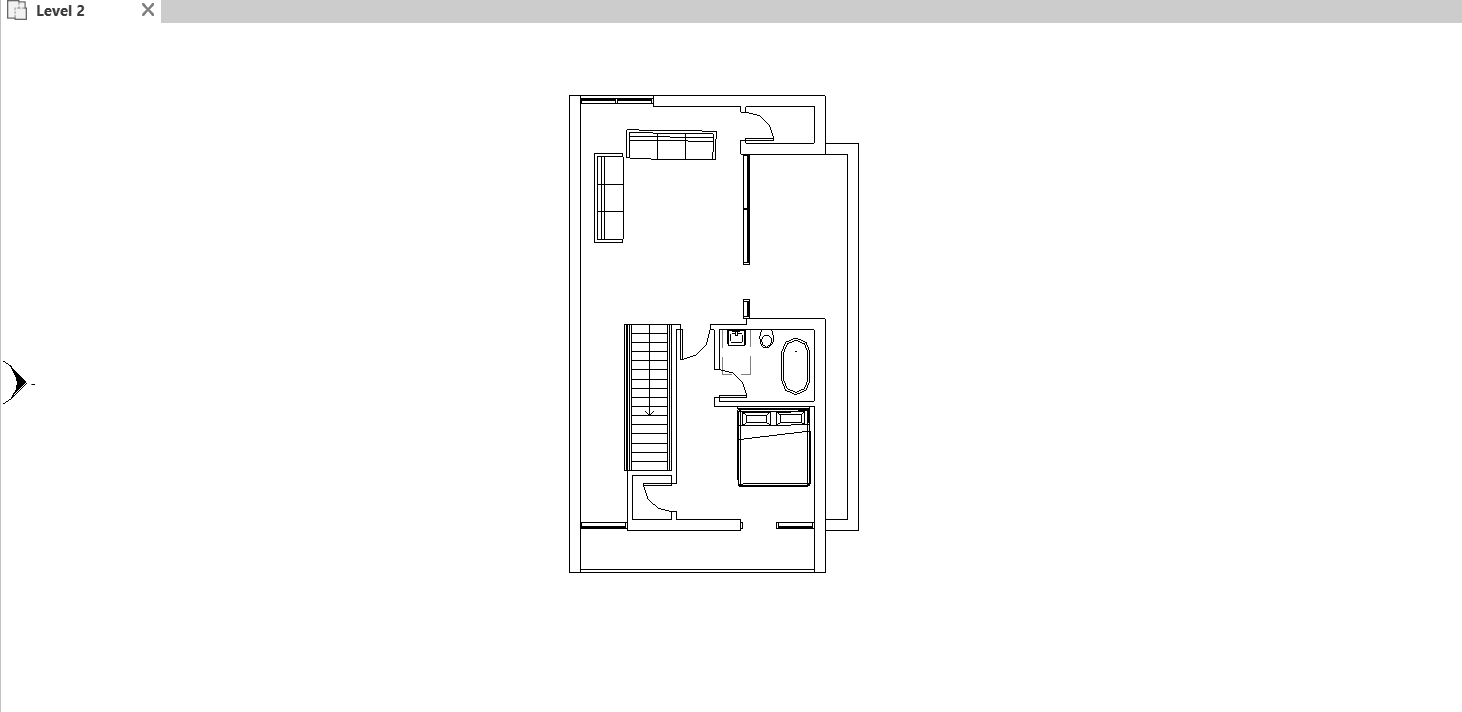
LEVEL 2
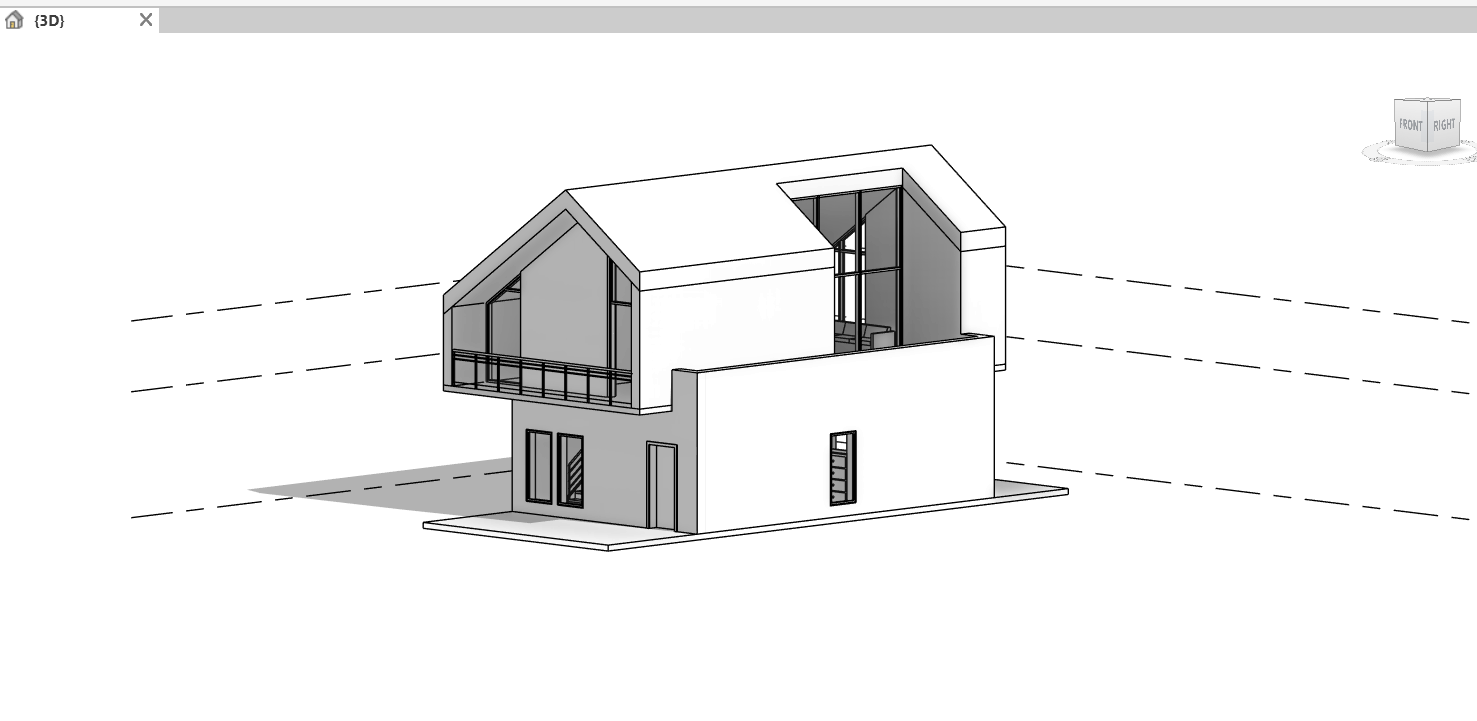
3D VIEW
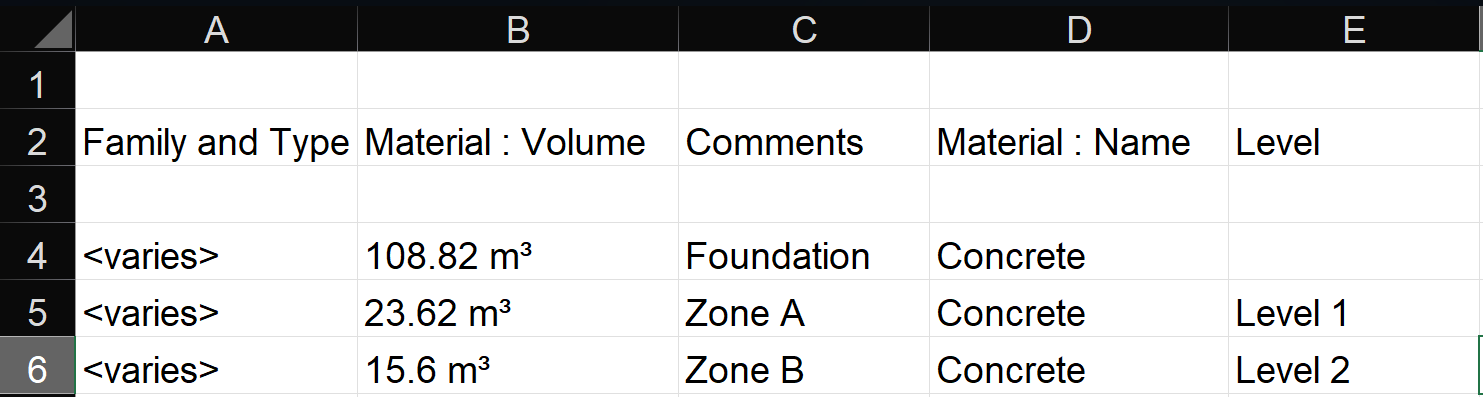
RAW DATA FROM REVIT
Step 2: IoT Data Simulation and Synthetic Dataset Generation
Because accessing continuous, multi-sensor live data from an active, large-scale construction site was practically impossible due to stringent budget limitations, safety protocols, and project scope constraints, a highly sophisticated Python-based data synthesis engine was engineered. Rather than utilizing static dummy data, the script leveraged advanced statistical libraries (NumPy, SciPy, and Pandas) to mathematically simulate a live IoT sensor network.
The simulated 150-day time-series dataset incorporated the following critical parameters, each governed by specific statistical distributions to ensure real-world fidelity:
Weather Impact (Ambient Temperature and Precipitation)
Labour Count and Workforce Availability
Equipment Downtime
Supply Delays
CO₂ Emissions
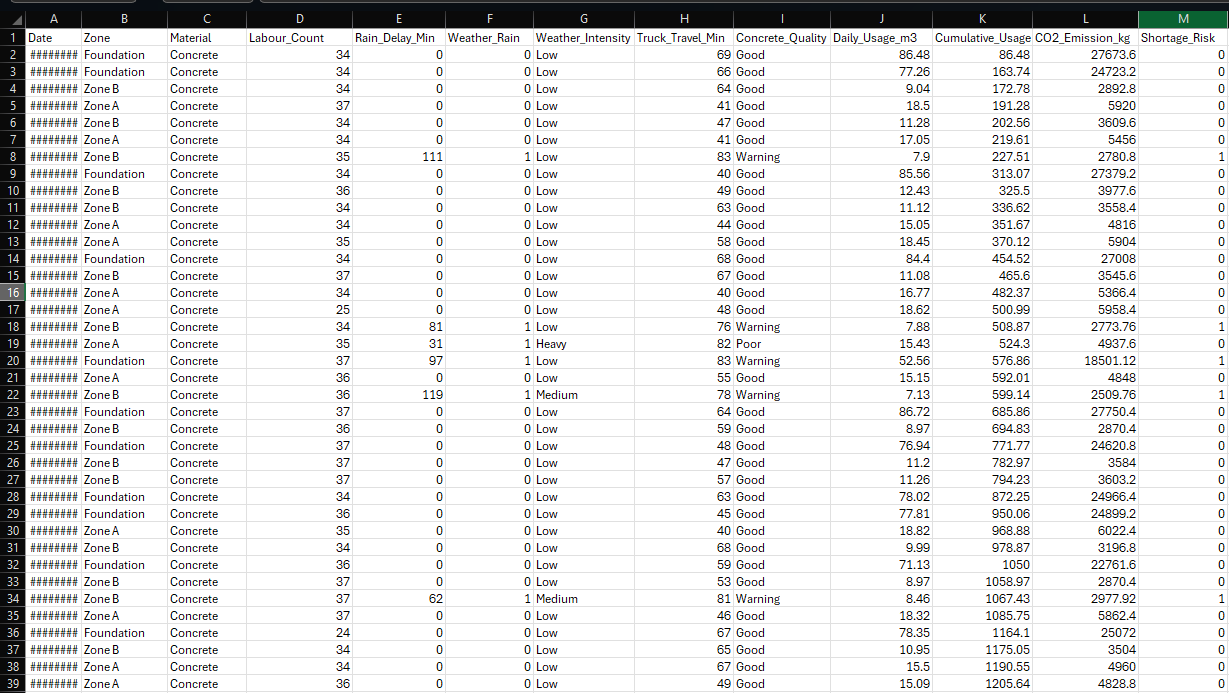
Snippet of the synthetically generated 150-day IoT dataset, illustrating the integration of stochastic environmental and operational variables.
Step 3: Data Preprocessing and Feature Engineering
Raw, simulated sensor data is inherently noisy and cannot be ingested directly into machine learning algorithms without risking severe model divergence. Rigorous preprocessing was executed utilizing Python’s Pandas and Scikit-Learn libraries:
Temporal Feature Decomposition: Time-series data inherently contains hidden periodicities. The continuous 150-day timeline was decomposed into discrete temporal features ('Day of Week', 'Is_Weekend', 'Month'). This allows algorithms to learn cyclic productivity trends (e.g., lower manual labour output on Sundays).
Categorical Encoding: Text-based categorical variables (e.g., Weather as 'Sunny', 'Rainy') cannot be processed by gradient-based models. These were transformed into a sparse numeric matrix using One-Hot Encoding, which strictly prevents the model from assuming false ordinal hierarchies between independent weather categories.
Feature Scaling and Normalization: Continuous variables with vastly different scales (e.g., Temperature ranging from 15–40°C vs. CO₂ emissions in thousands of units) distort distance calculations in ML space
Step 4: Machine Learning Modelling and Validation
To prevent "data leakage", a catastrophic error in time-series forecasting where future data accidentally informs past predictions, the pre-processed dataset was split chronologically rather than randomly. The first 80% (120 days) was allocated as the Training Set, while the subsequent 20% (30 days) served as the unseen Testing Set.
Three fundamentally different ensemble architectures (Random Forest, XGBoost, and LightGBM) were instantiated to predict the dependent variable target (y): "Daily Concrete Usage". Hyperparameter optimization was aggressively pursued using GridSearchCV. We mapped a multi-dimensional parameter space to optimize constraints such as maximum tree depth, learning rate and the number of estimators, mathematically minimizing the empirical risk of model overfitting.
Step 5: Prediction and Rolling Forecasting
Once mathematically converged and validated, the models were deployed for realworld application: generating a rolling 7-day forecast. By inputting the anticipated environmental variables and planned labour allocation for the upcoming week, the predictive pipeline acts as an auto-regressive forecaster. It calculates the exact maximum volume of material that the current workforce and site conditions can realistically consume. This fundamentally shifts project management into a proactive paradigm, facilitating highly efficient, Lean Construction practices such as Just-In- Time (JIT) material ordering, thereby virtually eliminating costly onsite material degradation and stockpiling.
V. RESULTS AND COMPARATIVE ANALYSIS
A. Model Performance and Algorithmic Comparison
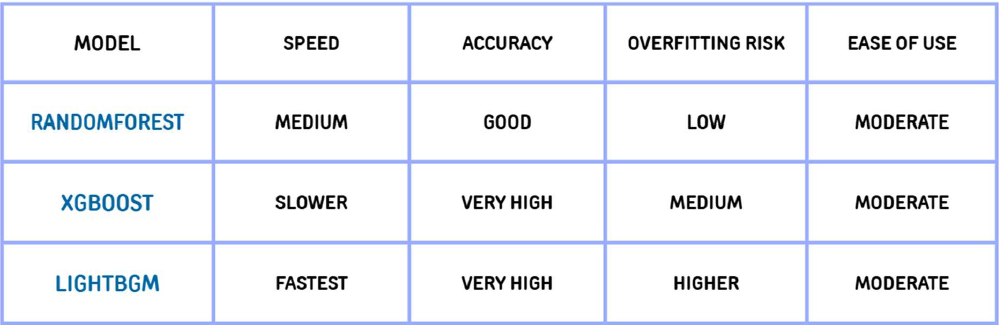
Comparative performance analysis and evaluation metrics of the deployed Machine Learning algorithms.
B. Key Findings and Model Interpretability
Modern machine learning models are often criticized as "black boxes." To solve this, advanced feature interpretation (evaluating Gini impurity decreases) was conducted.
Beyond base accuracy metrics, the "Feature Importance" array yielded profound insights into the underlying physics of construction delays.
Empirical data extraction revealed that environmental volatility (specifically, precipitation impact) and human capital availability (worker count) carried the most profound statistical weight in determining the daily concrete output. Surprisingly, while catastrophic equipment downtime was highly impactful on an individual day, its overall statistical importance over the 150-day lifecycle was secondary to continuous, low-level labour shortages and weather disruptions.
C. Impact on Construction Management and Economics
The implications of these empirical findings represent a paradigm shift for civil engineering management. By leveraging this unified BIM-IoT-ML platform, the quantification of future risk is transformed from a speculative human assumption into a mathematically rigorous calculation.
If the XGBoost model outputs a high-confidence prediction of a 40% drop in concrete placement due to an approaching weather front compounded by statistical labour absenteeism, the project manager is empowered with actionable, data-driven intelligence. Dispatch orders for high-grade cement transit mixers can be proactively delayed or scaled down. This directly eliminates the pervasive industry scenario where time-sensitive materials expire on site and workers are compensated for idle time, thereby drastically optimizing the project's capital efficiency, radically minimizing carbon-intensive material wastage, and ensuring strict adherence to the critical path timeline.
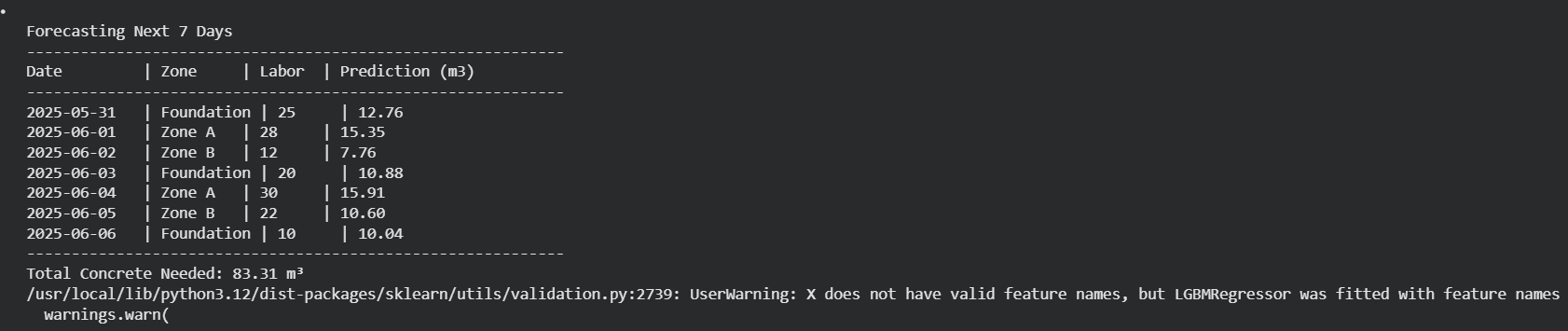
7-Day Machine Learning Forecast for Concrete Demand
VI. PLATFORM DEPLOYMENT (STREAMLIT INTEGRATION)
A highly accurate predictive machine learning model possesses little practical utility if it remains confined to a Python script or a localized Jupyter Notebook, accessible only to data scientists. In the high-paced environment of a construction site, project managers and civil engineers require instantaneous, intuitive access to data without needing to comprehend the underlying algorithmic complexities. To solve this critical bottleneck, the entire Python machine learning backend was encapsulated and deployed via a Streamlit Web Platform.
Streamlit is an advanced, open-source Python application framework specifically engineered for machine learning and data science workflows. It allows for the rapid development of reactive Graphical User Interfaces (GUIs) that seamlessly integrate with backend Scikit-Learn pipelines and Pandas data frames. The deployed web dashboard functions as a comprehensive Decision Support System (DSS), transforming raw model outputs into actionable, visual intelligence through the following core features:
1. Seamless Data Ingestion and Pipeline Execution
2. Interactive Parameter Adjustment via GUI
3. Real-Time Visualization and Forecasting
4. Proactive Alert System and Bottleneck Detection
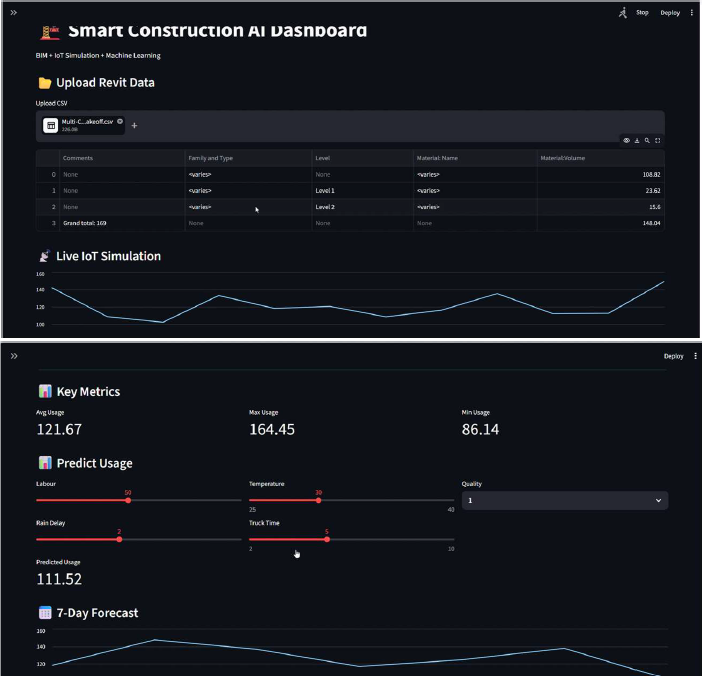
The Streamlit Interactive Web Dashboard for Real-Time Resource Forecasting. The
interface highlights the user-friendly sidebar for dynamic parameter adjustment
(simulating future weather and labour conditions) and the primary visualization pane
displaying the ML-driven resource demand output.
VII. CONCLUSIONS
The construction industry's reliance on manual tracking and disjointed systems is no longer sustainable. This project successfully demonstrates that the deep integration of Building Information Modelling (BIM), Internet of Things (IoT) simulation, and Machine Learning (ML) fundamentally revolutionizes resource monitoring. By utilizing Revit to establish structural truths and simulating real-world IoT data to represent site chaos, we created a comprehensive environment for AI to thrive. The comparative analysis revealed that XGBoost provided unparalleled accuracy, while LightGBM offered exceptional speed. Crucially, encapsulating this complex AI within an intuitive Streamlit web platform ensures that site engineers have immediate, actionable access to predictive insights. Ultimately, this system reduces project delays, minimizes excessive cost overruns, limits material wastage, and pushes the industry closer to highly predictive, proactive construction planning.
VIII. FUTURE SCOPE AND SCALABILITY
While the current prototype successfully demonstrates the immense potential of integrating BIM, simulated IoT data, and predictive Machine Learning, it currently operates as a localized Proof-of-Concept (PoC). To transition this framework into a commercially viable, enterprise-grade solution capable of handling multi-milliondollar mega-projects, several ambitious technological enhancements are proposed for future iterations:
1. Real-Time Physical IoT Edge Integration and Telemetry
The most immediate necessary evolution is transitioning from the Python-based synthesized dataset to a fully physical, live-streaming IoT edge network. This will involve deploying tangible sensor hardware across the construction site and routing
the telemetry through high-throughput, low-latency streaming platforms like Apache Kafka or AWS Kinesis. Specific hardware implementations would include:
RFID and BLE Beacons: Attached to raw material shipments and transit mixers to provide real-time, GPS-enabled supply chain tracking.
Telematics on Heavy Machinery: Integrating API data directly from crane and excavator onboard computers to monitor engine RPM, fuel consumption, and exact failure diagnostics instead of relying on Boolean simulation.
Biometric and Wearable Sensors: Utilizing smart helmets or biometric turnstiles to precisely track labour distribution across different zones of the construction site in real-time, ensuring the ML model trains on highly accurate human-capital data.
2. Bidirectional Digital Twin Synchronization (4D and 5D BIM)
Currently, the BIM data is extracted statically. The ultimate evolution of this platform involves the realization of a bidirectional "Digital Twin." By feeding the Machine Learning outputs back into advanced construction sequencing software (such as Autodesk Navisworks or Bentley SYNCHRO), the system can achieve true 4D (Time) and 5D (Cost) BIM integration. In this environment, the 3D structural model would dynamically change colour based on predictive algorithms, for example, a concrete slab might glow red if the XGBoost model predicts a supply delay, or green if the critical path is on schedule. This visual, spatial representation of algorithmic data would drastically reduce the cognitive load on site engineers.
3. Cloud-Native Architecture and Mobile Edge Deployment
To ensure global scalability, fault tolerance, and high availability, the current localized Streamlit deployment must be upgraded to a robust, cloud-native microservices architecture hosted on AWS, Microsoft Azure, or Google Cloud Platform (GCP). By containerizing the machine learning models using Docker and orchestrating them via Kubernetes, the platform could simultaneously process data from dozens of independent construction sites. Furthermore, a dedicated iOS and Android mobile application would be developed. This extends the platform's reach directly to the edge, utilizing push-notification protocols to send instantaneous delay-warnings and automated re-ordering suggestions straight to the pockets of foremen and site managers operating in the field.
4. AI-Driven Unsupervised Anomaly Detection
The current predictive pipeline relies entirely on supervised learning (predicting known target variables). Future scope includes integrating unsupervised machine learning algorithms, such as Isolation Forests or Deep Autoencoders, to continuously monitor the live data streams for irregular patterns without prior labelling. This AIdriven anomaly detection would act as an automated auditing system, capable of flagging real-time financial fraud (e.g., material requisition rates vastly exceeding structural placement rates), unauthorized removal of inventory, or severe safety hazards (e.g., detecting unusual clustering of labour in high-risk zones during unauthorized hours).
5. Comprehensive Multi-Resource and ESG Prediction
While the current mathematical models focus primarily on predicting the consumption of primary structural materials (concrete and steel), the framework’s feature space must be aggressively expanded. Future models will predict dynamic site energy consumption (kWh) and real-time financial cash-flow burn rates
(integrating with Earned Value Management systems). Most importantly, aligning with global Environmental, Social, and Governance (ESG) mandates, the platform will be expanded to forecast the total lifecycle carbon footprint (Scope 1, 2, and 3 emissions), enabling construction firms to dynamically optimize their operations to meet stringent net-zero environmental targets.
IX. REFERENCES
[1] R. Sacks, C. Eastman, G. Lee, and P. Teicholz, BIM Handbook: A Guide to Building Information Modelling for Owners, Designers, Engineers, Contractors, and Facility Managers. 3rd ed., Hoboken, NJ: John Wiley & Sons, 2018.
[2] L. Chen, H. Luo, and X. Yin, "Integrating BIM and IoT for smart construction management," Automation in Construction, vol. 90, pp. 1-12, 2018.
[3] T. Chen, and C. Guestrin, "XGBoost: A Scalable Tree Boosting System," Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794, 2016.
[4] G. Ke et al., "LightGBM: A Highly Efficient Gradient Boosting Decision Tree," Advances in Neural Information Processing Systems, vol. 30, pp. 3146-3154, 2017.
[5] GitHub Repository
X.
MENTEES
Piyush Chouhan
Sreenidhi Golamaru
MENTORS
Bidisha Koley
Saranksh TR
Yash Kedia
Report Information
Team Members
Team Members
Report Details
Created: April 8, 2026, 2:31 a.m.
Approved by: Dhruv Kiran Gandhi [Piston]
Approval date: None
Report Details
Created: April 8, 2026, 2:31 a.m.
Approved by: Dhruv Kiran Gandhi [Piston]
Approval date: None