

PathFinder: A Graph-Based Career Discovery Platform
Abstract
Abstract
Aim
To develop a web-based platform featuring a dual-sided recommendation engine. The system enables candidates to upload their resume and other details to receive targeted job matches, and allows recruiters to post job vacancies and receive automatically recommended candidate profiles.
Introduction
Traditional applicant tracking systems often rely on basic keyword matching, while manual headhunting is time consuming. Developing effective recommender systems for recruitment faces unique challenges, primarily the severe cold-start problem caused by the short lifespan of job postings and candidates, along with strict temporal constraints where recommendations cannot be made too far in the past or future. To address these issues, this project implements a recommendation engine based on the TIMBRE framework. It integrates diverse data sources, such as candidate resumes and job descriptions, into a unified temporal heterogeneous graph, allowing for accurate, time-aware job and candidate matching.
Literature Survey
1. Traditional Job Recommendation and Screening Systems
Existing approaches frequently model job recommendation as a collaborative filtering problem, where candidates are recommended jobs based on the behavior of similar users. However, these systems struggle with data accessibility due to privacy constraints. Alternatively, natural language processing (NLP) has been widely adopted for automated resume screening and parsing. While useful for filtering a pre-selected pool of applicants for a specific role, NLP methods are ineffective for proactive candidate headhunting and rely on the assumption that resume data is entirely accurate. Recent studies have explored Large Language Models (LLMs) for candidate matching, but current frameworks face significant scalability challenges when ingesting thousands of resumes.
2. Graph-Based Recommendation Architectures
Graph-based recommender systems typically formulate the task as link prediction, determining the likelihood of a connection between a user and an item. Heterogeneous graphs are particularly advantageous as they capture connected data and rich semantic information, which can be processed using Graph Neural Networks (GNNs) such as Graph Convolutional Networks (GCNs) or Graph Attention Networks. A primary limitation in graph construction for recruitment is the scarcity of node features, which sometimes necessitates the integration of external knowledge bases.
3. Temporal and Sequential Recommendation Models
Accounting for time is critical in recommendation domains to capture evolving preferences. Standard temporal models utilize architectures like Recurrent Neural Networks (RNNs) or Temporal Graph Networks (TGNs) to update node embeddings over time. Sequential recommendation methods aim to predict the next interaction; however, these models require a minimum threshold of prior interactions to function effectively, making them highly susceptible to the cold-start problem inherent in the short lifespan of job postings.
4. Data Limitations in Current Research
While public datasets for temporal recommendations exist, they are heavily anonymized and contain very limited side information regarding the users. Furthermore, these datasets generally assume a high density of historical interactions for most users and items. This assumption does not hold true for the recruitment sector, establishing a critical need for systems capable of balancing external side information with sparse interaction data.
Technologies Used:
- Core Programming Language: Python
- Graph Neural Network & Machine Learning: PyTorch, PyTorch Geometric (PyG)
- Data Processing & Analytics: NumPy, Pandas
- Backend: Django
- Frontend: React, three.JS
Methodology
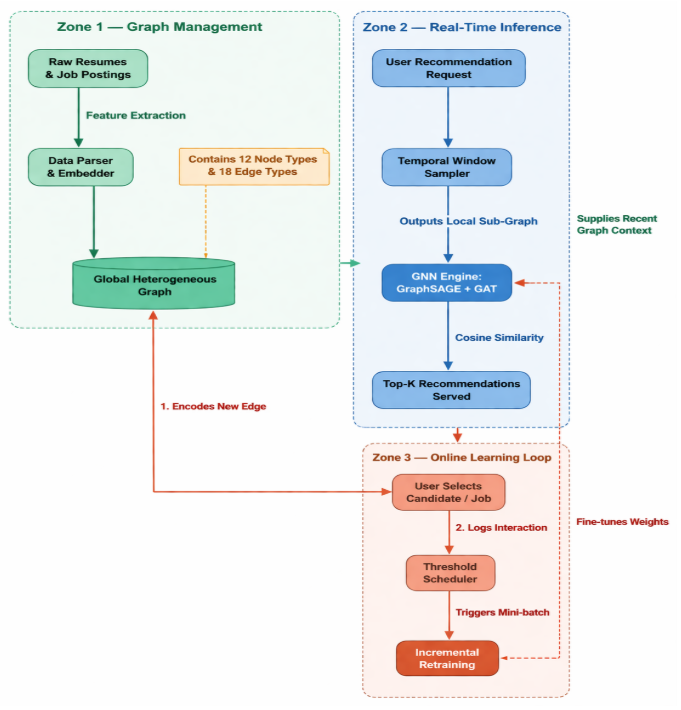
A) Graph Construction and Training:
Graph Construction
- Data Representation: Information extracted from candidate profiles and job postings is structured into a temporal heterogeneous graph.
- Node Types: The graph consists of exactly 12 node categories: candidate, job, skill, contract, origin, experience, salary, category, company, concept, time and shortlist.
- Edge Types: Nodes are interconnected using 18 distinct edge types, resulting in 36 total edge types when accounting for bidirectional relationships.
- Shortlist Nodes: Direct candidate-job interactions are reified into "shortlist nodes". A shortlist node sits between a candidate and a job, holding the interaction timestamp to simplify temporal tracking and dynamic negative sampling.
- Temporal Nodes: Dedicated temporal nodes, representing the passage of time (e.g., months), connect to candidates, jobs, and shortlist nodes to enforce recency constraints.
Sampling Strategy
- Temporal Window Sampling: The system employs a fixed recent window sampling strategy. When querying a target job, it samples candidates strictly from a defined recent period preceding the job's creation, and vice versa.
- Temporal Filtering: The sampling algorithm strictly masks future events, ignoring candidates, jobs, or shortlists created after the target interaction time to prevent data leakage.
Graph Architecture
- Task Formulation: The core objective is framed as a link prediction task, calculating the probability of a connection between a specific shortlist node and a job node.
- Embedding Initialization: Each node is assigned a time-independent base embedding, which is linearly combined with its respective feature vector.
- Convolution and Attention Layers: The network processes the sub-graph embeddings using a combination of GraphSAGE (Graph Sample and Aggregate) and Graph Attention Network (GAT) layers to dynamically weigh and aggregate structural and relational data.
- Similarity Scoring: The final output representations for the shortlist node and the job node are compared using cosine similarity to generate the final recommendation ranking score.
B) Inference
- Dynamic Node Instantiation: Upon registration, new entities (candidates or recruiters/jobs) are dynamically injected into the active graph. Textual inputs, such as resume summaries or job descriptions, are immediately processed into vector embeddings to initialize the new node's features.
- Relational Edge Mapping: The system automatically parses the new user's structured data and establishes edges to existing attribute nodes within the graph. For example, if a candidate lists "Python," an edge is instantly created linking their new candidate node to the existing "Python" skill node.
- Interactive Recommendation & Reification: When a recommendation is requested, a temporal "shortlist node" is instantiated and attached to the querying candidate or recruiter. The system runs the inference pipeline to serve the top-k matched profiles or jobs.
- Interaction Encoding: When a user acts on a recommendation (e.g., a candidate selects a job, or a recruiter selects a candidate), this interaction is permanently captured by creating a new edge connecting the chosen entity node to the newly created shortlist node.
- Continuous Graph Persistence: The architecture maintains a single, persistent global graph state. Throughout the entire application lifecycle, all newly registered entities, generated shortlist nodes, and user interactions are continuously appended to this unified graph, ensuring subsequent inferences leverage the most up-to-date structural context.
C) Online learning
Graph based interaction learning: the system models candidate-job relationships as a heterogeneous graph and performs prediction, using user interactions as positive sample for training.
- Dynamic: Employs an incremental training strategy for online learning. The model is updated using mini batches of recent interaction data, hence avoiding full retraining. Previously learned weights are preserved and fine-tuned during the retraining process, allowing the model to adapt continuously.
- Retraining pipeline: Threshold triggered based on number of interactions- using a lightweight scheduler to monitor and log interactions and triggers retraining when a predefined threshold is reached. With user interactions and real time graph augmentation, new information is incrementally incorporated into the model, which is then used for improved future predictions.
Results
Training and Validation Performance
Early stopping at the 58th epoch along with hyperparameter tuning using the GraphSAGE convolution gave the following results:
- AUC: 0.9404
- Precision: 0.8609
- Recall: 0.9892
- Accuracy: 0.9147
- F1 Score: 0.9206
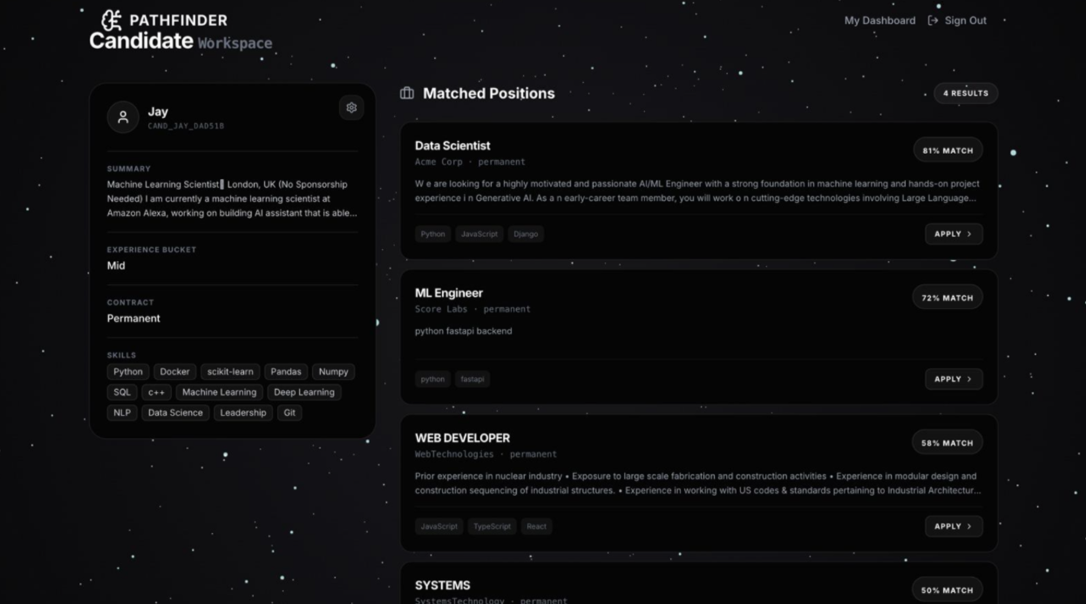
Here is our web-based interactive platform.
Comparison with Baseline Models
To evaluate the relative effectiveness of our architecture, the primary classification metrics (AUC and Precision) were compared against several state-of-the-art temporal graph and sequential recommendation baselines.
| Model | AUC | Precision |
|---|---|---|
| Proposed GraphSAGE Model | 0.9404 | 0.8609 |
| TGN |
0.4283 (SD 0.0607) |
0.4579 (SD 0.0116) |
| NAT |
0.7893 (SD 0.0091) |
0.7938 (SD 0.0097) |
|
DYREP |
0.7489 (SD 0.0052) |
0.7375 (SD 0.0046) |
|
TGSRec |
0.7175 (SD 0.1007) |
0.8605 (SD 0.0457) |
Conclusion
This project successfully designed and implemented a web based recommendation platform tailored for the highly dynamic recruitment sector. By modelling candidate-job relationships as a temporal heterogeneous graph, the system effectively addresses the prevalent cold-start problem and the strict temporal constraints inherent in hiring. The architecture moves beyond static offline training by incorporating dynamic node instantiation, real-time edge mapping, and an incremental online learning loop. Utilizing a combination of GraphSAGE and GAT layers, the platform accurately captures both structural and semantic data, providing highly relevant, personalized recommendations for both job seekers and professional recruiters in a live environment.
Future Scope
- Optimizing Inference Latency: As the global graph scales with new user registrations and interactions, optimizing the computational efficiency of the graph traversal and embedding aggregation will be critical to maintaining real-time recommendation speeds.
- Advanced Graph Sampling: Enhancing the current temporal window approach by developing more robust and intelligent sampling strategies. This will allow the system to capture deeper collaborative signals
- GNN-Powered Discovery Feed: Expanding the platform's utility by introducing a dynamic interaction feed. This feature would leverage the existing GNN engine, which outperforms standard collaborative filtering in effectively recommending short-lived nodes like fast moving opportunities or trending content.
References
- TIMBRE: Efficient Job Recommendation On Heterogeneous Graphs For Professional Recruiters
- Inductive Representation Learning on Large Graphs
GitHub Repository
All the source codes can be found here.
Member Details
Mentees
- Devansh Sharma
- Priyadarshini S
- Ruchir Sreepada
- Vivek Kashyap
Mentors
- Atharva Atul Rege
- H S Jayanth
- Prahas
Report Information
Team Members
Team Members
Report Details
Created: May 10, 2026, 4:38 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 10, 2026, 4:38 p.m.
Approved by: None
Approval date: None