

WizGuide
Abstract
Abstract
Github Repository: https://github.com/Abhishek-Sulakhe/WizGuide-Envision-26.git
Google Meet Link: https://meet.google.com/uzn-cotv-fta
Aim
The aim of WizGuide is to create an intelligent domain-specific AI assistant capable of answering questions related to the Harry Potter universe with high contextual accuracy.
The project focuses on implementing Retrieval-Augmented Generation (RAG) techniques to improve factual correctness and semantic understanding. The system combines dense retrieval, sparse retrieval, query expansion, and reranking to ensure highly relevant responses.
WizGuide also serves as an educational implementation of modern NLP and AI retrieval architectures
Introduction
Recent advancements in Artificial Intelligence and Natural Language Processing have enabled the development of highly interactive conversational systems. However, traditional Large Language Models often struggle with domain-specific factual retrieval and may generate hallucinated information.
Retrieval-Augmented Generation (RAG) solves this problem by combining information retrieval systems with language generation models. Instead of relying solely on pre-trained model memory, RAG retrieves external contextual documents before generating a response.
WizGuide applies this concept specifically to the Harry Potter universe. Users can ask questions about:
- Characters
- Spells
- Magical creatures
- Hogwarts houses
- Events
- Locations
- Lore and storyline details
The project demonstrates how hybrid retrieval systems can significantly improve the quality and relevance of AI-generated responses.
System Architecture Diagram
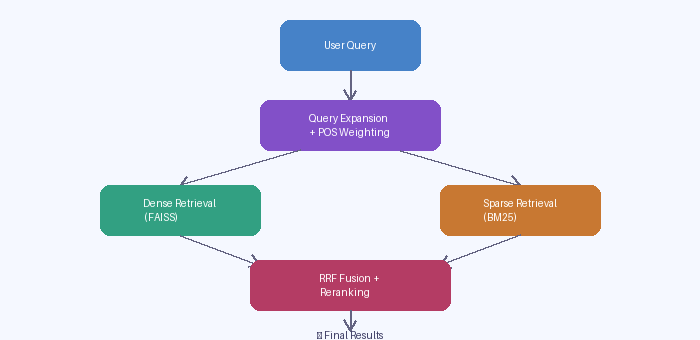
Literature Survey
The development of WizGuide is inspired by several modern research areas in Artificial Intelligence and Information Retrieval.
1. Retrieval-Augmented Generation (RAG)
RAG systems improve response quality by retrieving contextual information before answer generation. This reduces hallucinations and increases factual accuracy.
2. Dense Vector Retrieval
Dense retrieval converts documents into embeddings and retrieves semantically similar documents using vector similarity search.
3. Sparse Retrieval using BM25
BM25 is a ranking algorithm widely used in search engines. It retrieves documents based on keyword frequency and importance.
4. Cross-Encoder Reranking
Cross-encoder models compare the query and retrieved documents together to improve ranking accuracy.
5. Query Expansion
Adding synonyms and related terms improves recall and enables better retrieval of semantically related information.
6. NLP-based Token Weighting
Part-of-speech tagging helps identify important entities such as proper nouns and named entities.
Technologies Used

Methodology
The WizGuide system follows a hybrid Retrieval-Augmented Generation pipeline.
Step 1: User Query Input
The user enters a Harry Potter-related question.
Step 2: Query Expansion
The system expands important nouns using WordNet synonyms to improve retrieval recall.
Step 3: POS-Based Token Weighting
spaCy NLP processing identifies proper nouns, nouns, and verbs. Important entities receive higher retrieval weights.
Step 4: Dense Retrieval
The query is converted into embeddings using HuggingFace sentence transformers. FAISS retrieves semantically similar documents.
Step 5: Sparse Retrieval
A custom BM25 implementation retrieves documents based on keyword relevance.
Step 6: Reciprocal Rank Fusion (RRF)
Dense and sparse retrieval results are combined using Reciprocal Rank Fusion to balance semantic similarity and exact matching.
Step 7: Cross-Encoder Reranking
The retrieved results are reranked using a cross-encoder model to improve contextual relevance.
Step 8: Final Response
The most relevant documents are returned to the user.
Workflow Diagram
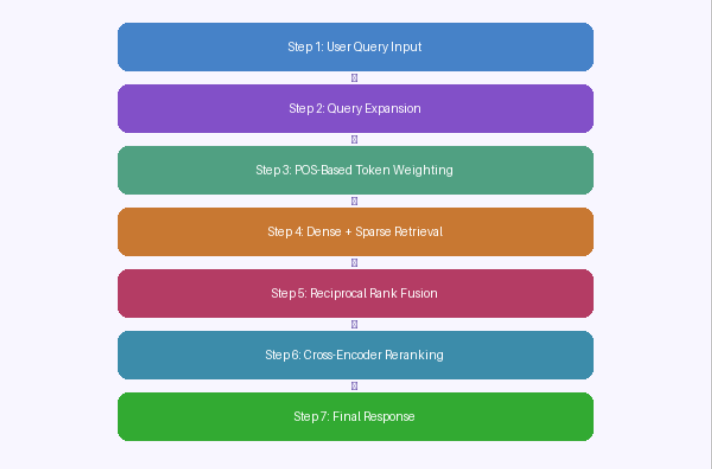
Custom BM25 Implementation
Unlike standard BM25 wrappers, WizGuide uses a custom hand-rolled BM25 implementation.
Advantages:
- Complete control over tokenization
- Adjustable k1 and b parameters
- Better handling of technical tokens
- Improved retrieval customization
The custom tokenizer preserves:
- CamelCase tokens
- Underscore-separated words
- Slash-separated identifiers
This improves search quality and document relevance.
Dense Retrieval using FAISS
FAISS is used for efficient vector similarity search. Documents are converted into embeddings using:
- all-MiniLM-L6-v2 sentence transformer model
Advantages:
- Fast similarity search
- Semantic understanding
- Efficient large-scale retrieval
- Better contextual matching
The vector database enables rapid document retrieval even for large datasets.
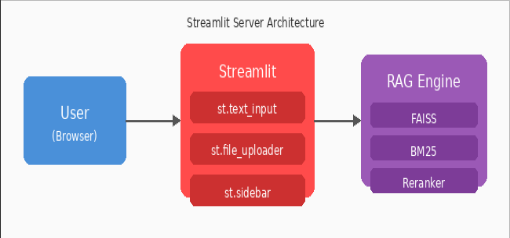
Server Architecture
The frontend interface is implemented using Streamlit.
Main UI Components:
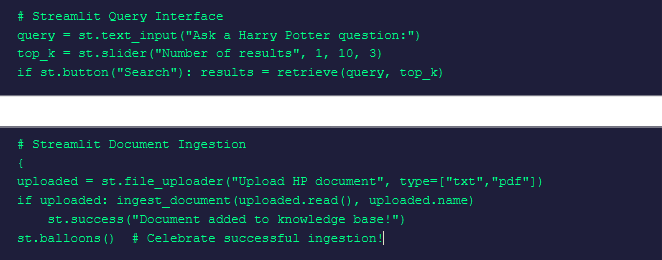
st.text_input (Query Box)
Accepts user queries through an interactive text input widget and displays retrieved results.
st.file_uploader (Document Ingestion)
Allows dynamic addition of new documents into the knowledge base.
st.sidebar (Status & Settings)
Displays system status, document count, and configuration settings in the sidebar panel.
The Streamlit frontend is modular and interactive, providing a clean user experience while remaining easy to extend for future cloud deployment.
API Architecture Diagram
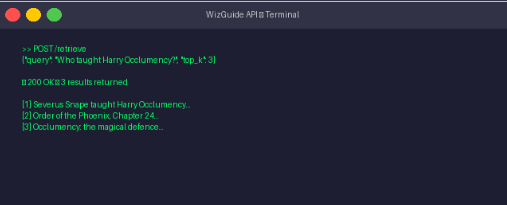
Sample API Usage
Results
The hybrid retrieval system produced significantly better retrieval accuracy compared to using only dense retrieval or sparse retrieval individually.
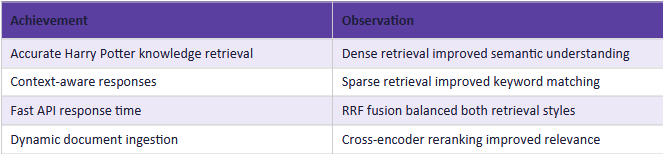
Result Screenshots
Conclusion
WizGuide successfully demonstrates the effectiveness of Retrieval-Augmented Generation for building intelligent domain-specific AI assistants.
The project integrates:
- Dense retrieval
- Sparse retrieval
- Query expansion
- NLP token weighting
- Cross-encoder reranking
The combination of these techniques improves retrieval accuracy and contextual understanding. The system also provides an interactive Streamlit frontend capable of supporting future AI integrations and real-time user interactions.
Future Scope
Future improvements for WizGuide include:
- Integration with Large Language Models (LLMs)
- Full conversational chatbot interface
- Cloud deployment
- Voice-based wizard assistant
- Multi-user authentication
- Expanded Harry Potter dataset
- Conversational memory support
- Real-time streaming responses
- Web frontend using React or Next.js
- Mobile application support
References
Research References:
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- FAISS Documentation
- Streamlit Documentation
- LangChain Documentation
- SentenceTransformers Documentation
Mentors and Mentees Details

Report Information
Team Members
Team Members
Report Details
Created: May 19, 2026, 11:41 a.m.
Approved by: None
Approval date: None
Report Details
Created: May 19, 2026, 11:41 a.m.
Approved by: None
Approval date: None