

Object Detection on KRIA KR260
Abstract
Abstract
Aim
Design and implement real-time image classification and object detection systems using an FPGA-based platform
Deploy a ResNet-based model for image classification and a YOLOv5-based model for object detection on a DPU accelerator, with each model implemented and evaluated separately
Achieve low-latency processing of input images from a live video stream
Develop a modular hardware–software co-design architecture supporting multiple CNN models
Introduction
The motivation for this project is to accelerate image processing tasks in autonomous systems using FPGA-based hardware for low-latency and power-efficient performance. In such systems, the ability to quickly and accurately classify and detect objects such as pedestrians, vehicles, and traffic signs is critical, as even small delays can impact safety and decision-making.
This project addresses this challenge by leveraging FPGA acceleration to speed up both image classification and object detection processes. A ResNet-based model is used for classification, while a YOLOv5-based model is used for detection, with each implemented and evaluated separately. By offloading computationally intensive operations to dedicated hardware, the system achieves faster performance compared to traditional software-based approaches.
This balance of speed and efficiency makes the solution well-suited for real-time autonomous and intelligent systems.
Technologies Used
- FPGA Platform – AMD Kria KR260 Robotics Starter Kit
- Hardware Design Tool – Vivado (for DPU configuration and bitstream generation)
- Embedded OS – PetaLinux (custom Linux image for the board)
- AI Toolchain – Vitis AI (for model quantization and compilation)
- Deep Learning Models – ResNet (image classification), YOLOv5 (object detection)
- Programming Languages – Python
- Libraries & Frameworks – OpenCV, NumPy, VART, XIR
- Communication – TCP/IP (for data transfer and monitoring)
- Input Device – USB Webcam (V4L2 interface)
Background Theory
ResNet –
ResNet (Residual Network) is a deep learning model widely used for image classification tasks. It introduces residual connections that help in training very deep neural networks by addressing the vanishing gradient problem. Instead of detecting objects, ResNet classifies the entire image into predefined categories, making it suitable for fast and efficient inference in real-time systems.
YOLOv5 –
YOLOv5 (You Only Look Once) is a deep learning model used for object detection. Unlike classification models, it identifies and localizes multiple objects within an image by predicting bounding boxes along with class labels. It performs detection in a single forward pass, making it highly suitable for real-time applications requiring both speed and accuracy.
PS –
The Processing System (PS) refers to the ARM-based processor on the KR260 board. It runs the operating system (PetaLinux) and handles high-level tasks such as control flow, data management, and post-processing operations like interpreting classification and detection outputs. The PS also manages communication, including capturing camera input and transmitting results.
PL –
The Programmable Logic (PL) is the FPGA fabric where custom hardware is implemented. In this project, the DPU (Deep Processing Unit) is deployed in the PL to accelerate the computationally intensive parts of the neural networks. By offloading inference to hardware, the PL enables faster and more efficient execution compared to running entirely on the PS.
PetaLinux –
PetaLinux is a Linux-based embedded operating system used on AMD/Xilinx FPGA platforms like the KR260. It is customized with the required drivers, libraries, and tools, including DPU support and the Vitis AI runtime. Running on the PS, it manages device control, communication, and execution of the inference applications, acting as a bridge between hardware (PL) and software.
Quantization (Vitis AI) –
Quantization converts a model from high precision (FP32) to lower precision (INT8) to reduce computational complexity and memory usage. This is essential for deploying models on the DPU, enabling faster inference with minimal accuracy loss, which is critical for real-time edge applications.
Methodology
Project Flow:
Set up development environment
Install Vivado, PetaLinux, and Vitis AI on the host system. Configure all dependencies required for hardware and software development.
Design and configure DPU in Vivado
Create the hardware design by integrating the DPU into the FPGA. Generate the bitstream and export the hardware description (.xsa).
Build custom PetaLinux image
Use the .xsa file to build a Linux image with DPU support. Include required drivers, libraries, and Vitis AI runtime.
Flash image and boot KR260
Write the PetaLinux image to an SD card and boot the board. Initialize the system and prepare it for deployment.
Train CNN models
Train the required models using appropriate datasets in PyTorch. A ResNet model is used for image classification, and a YOLOv5 model is used for object detection, with each trained and handled separately. Generate trained model files (.pt/.pth).
Quantize models (INT8)
Convert the trained models from FP32 to INT8 using Vitis AI. Reduce computation and make them suitable for DPU execution.
Compile models to .xmodel
Compile the quantized models using the DPU architecture file. Generate hardware-specific executable models (.xmodel).
Deploy models to KR260
Transfer the compiled models to the FPGA board using SSH/SCP. Prepare the system for running inference.
Capture live video
Use a USB webcam to capture real-time input frames. Feed the video stream into the processing pipeline.
Perform inference on DPU
Run the deployed models on the DPU for fast inference. ResNet performs image classification, while YOLOv5 performs object detection, executed separately depending on the application.
Display/stream output
Send the processed frames to the laptop via TCP. Display real-time results, including class labels for classification and bounding boxes for detection.
This project implements real-time image classification and object detection pipelines using the AMD Kria KR260 platform, which combines an ARM-based Processing System (PS) with FPGA-based Programmable Logic (PL). This heterogeneous architecture enables efficient execution by assigning control and lightweight tasks to the PS, while accelerating compute-intensive operations in the PL.
The Processing System (PS) runs PetaLinux and handles high-level functions such as camera interfacing, data handling, and displaying inference results. The Programmable Logic (PL) hosts the Deep Processing Unit (DPU), which accelerates deep learning inference for both models. A ResNet model is used for image classification, while a YOLOv5 model is used for object detection, with each executed separately. This division enables low-latency and power-efficient performance suitable for real-time applications. Communication between the PS and PL is carried out through AXI interfaces, ensuring fast data transfer and coordination between software and hardware components.
System Architecture and Data Flow
The system implements separate pipelines for image classification and object detection, with each executed independently based on the application.
Image Classification Pipeline (ResNet):
-
The PS captures live video input from a USB webcam using OpenCV.
- Captured frames are preprocessed (resizing and normalization) before inference.
- The processed frames are sent to the DPU in the PL for execution.
DPU (in PL):
- Performs deep learning inference on input frames
- Generates classification outputs (class probabilities)
- The outputs are sent back to the PS for post-processing.
- The PS interprets the predicted class labels.
- Final results are displayed or streamed to a laptop in real time.
Object Detection Pipeline (YOLOv5):
- The PS captures live video input from a USB webcam using OpenCV.
- Captured frames are preprocessed (resizing and normalization) before inference.
- The processed frames are sent to the DPU in the PL for execution.
DPU (in PL):
- Performs deep learning inference on input frames
- Generates raw detection outputs (feature maps)
- The outputs are sent back to the PS for post-processing.
- The PS performs decoding and Non-Maximum Suppression (NMS) to filter detections.
- Final frames with bounding boxes are displayed or streamed to a laptop in real time.
Results
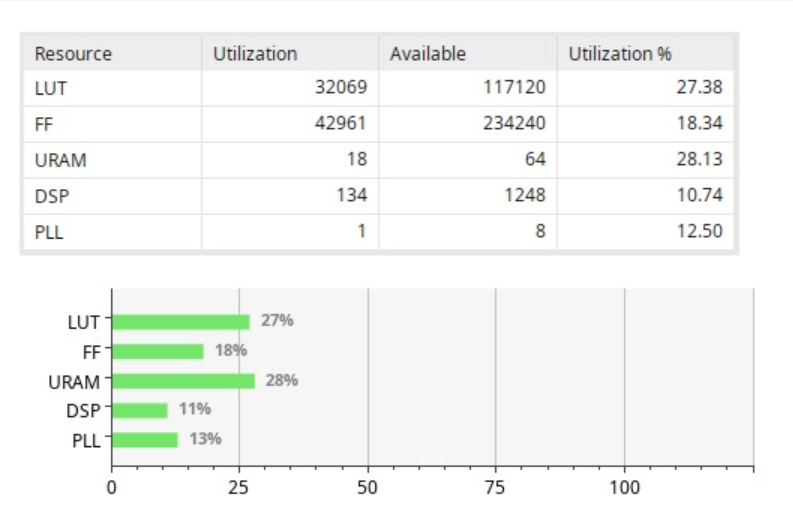
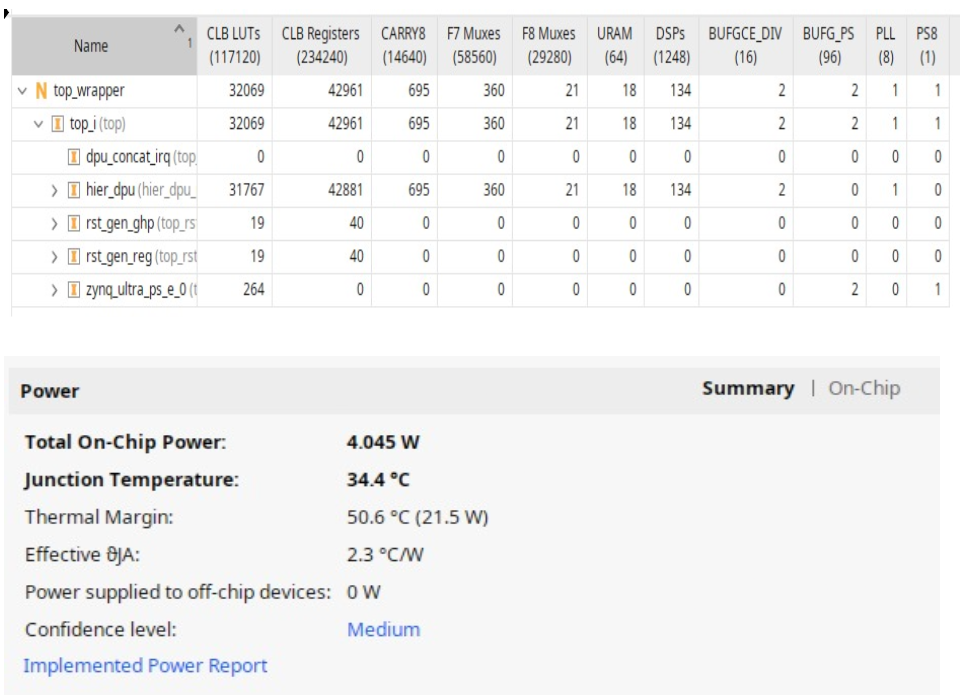
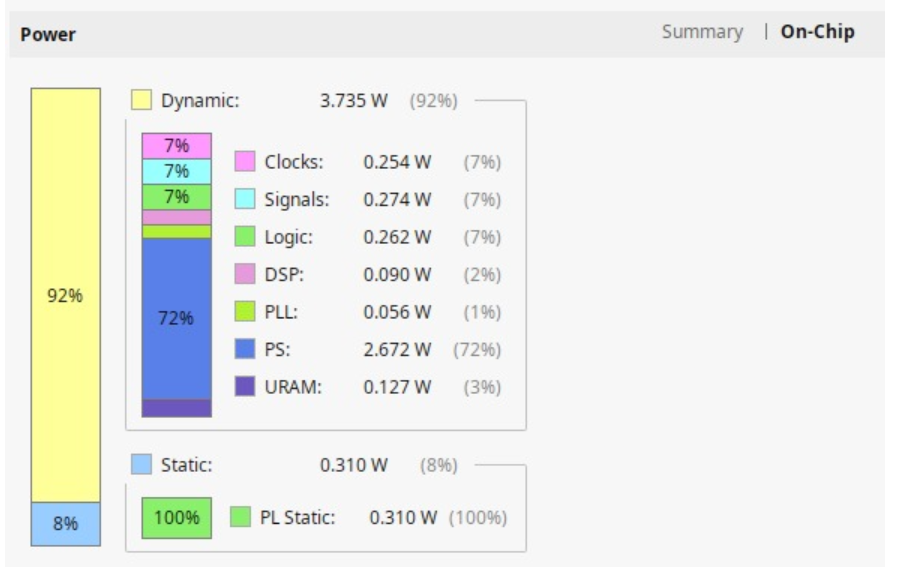
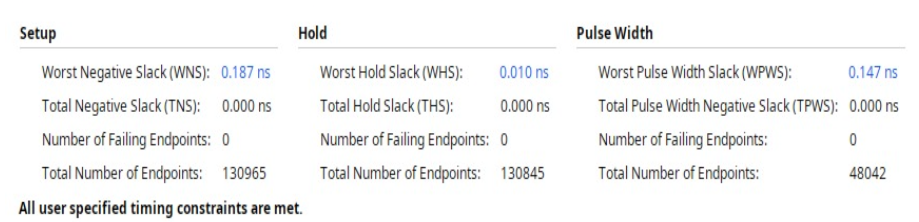
Utilization Report of DPU:
YOLO Model Results:
- The YOLOv5 model was successfully deployed on the DPU and performed real-time object detection on live camera input.
- The system generated bounding boxes with class labels (e.g., car, truck) and confidence scores for multiple objects per frame.
- The end-to-end pipeline from camera input to detection output was fully functional, establishing a complete hardware–software flow.
- Inference latency was observed to be approximately 240–250 ms per frame (~4 FPS).
- The DPU handled the majority of convolutional computations, while post-processing (e.g., NMS) was performed on the PS.
- A complete end-to-end deployment pipeline was successfully implemented, from model training and quantization to real-time inference on the FPGA.
- The system demonstrates functional real-time detection, but requires further optimization for robust real-world performance.



ResNet Model Results:
- The ResNet-based model demonstrated stable and consistent real-time performance on the DPU.
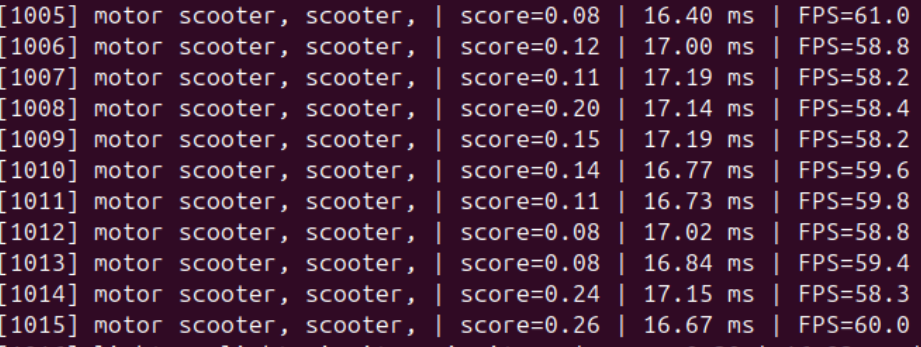
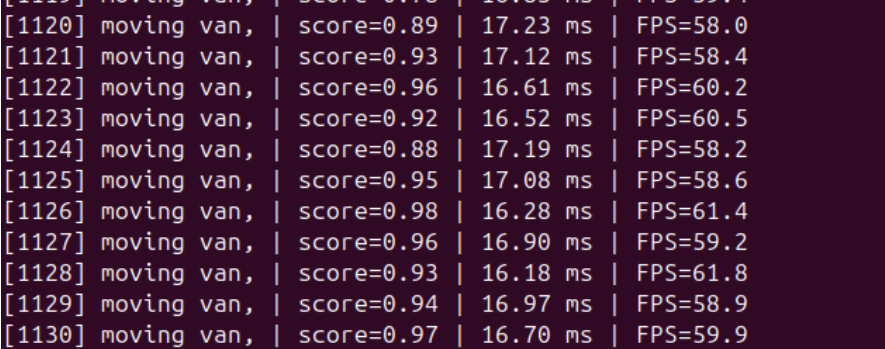
- Inference latency remained around 16–17 ms per frame, achieving approximately 58–62 FPS.
- The model showed high confidence scores (typically 0.85–0.98) for correct classifications such as “moving van”.
- Predictions were consistent across consecutive frames, indicating good temporal stability.
- Occasional low-confidence or incorrect classifications (e.g., “printer” with low score) were observed but were infrequent.



Performance Comparison (Hardware vs Software)
The ResNet model deployed on the DPU achieved an inference latency of approximately 16–17 ms per frame (~58–62 FPS). In comparison, typical software-based implementations of ResNet on a CPU achieve significantly lower performance, often in the range of 5–15 FPS, depending on the processor and optimization level. Even on GPUs, while higher throughput can be achieved, power consumption is considerably higher.
This demonstrates that FPGA-based acceleration provides a strong balance between performance and energy efficiency, delivering near real-time or real-time inference speeds with lower power requirements compared to conventional CPU-based approaches.
Conclusion
This project demonstrated the implementation of CNN models on the AMD Kria KR260 using Vitis AI. A ResNet model for classification and a YOLOv5 model for object detection were successfully deployed and executed separately on the DPU.
While the ResNet model achieved stable and low-latency classification performance, the YOLOv5 model served as the primary highlight by enabling real-time object detection with bounding boxes and class labels directly on the FPGA. The system successfully detected multiple objects per frame with reasonable confidence, demonstrating a complete end-to-end detection pipeline from camera input to hardware-accelerated inference.
Although YOLOv5 operated at a lower frame rate and showed some limitations with small or distant objects, it effectively showcased the capability of deploying complex detection models on FPGA hardware. Overall, the project highlights the strength of FPGA-based acceleration in handling advanced vision tasks like object detection, along with the trade-offs between speed, accuracy, and model complexity.
Future Scope
- Explore more efficient detection models for FPGA deployment.
- Explore Binary Neural Networks (BNNs) for ultra-low power and faster inference on FPGA.
Team Members
Mentors
- Adithya A
- Adithya Santhanam
- Prateek Goel
Mentees
- Shouryadip Chakraborty
- Daksh Singh
- Abhishek Agrawal
- Abhinav S Rao
Report Information
Team Members
Team Members
Report Details
Created: May 29, 2026, 6:07 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 29, 2026, 6:07 p.m.
Approved by: None
Approval date: None