

TradeX
Abstract
Abstract
Aim:
The aim of this project is to design and implement a functional, low-latency order matching engine that mirrors the core components of a real-world exchange matching system. The system must be capable of:
• Accepting and classifying multiple order types from an OMS layer
• Matching buy and sell orders using price-time priority
• Publishing trade events to consumers through lock-free inter-process communication
• Handling advanced order semantics such as stop-loss triggers and iceberg slicing
Introduction:
Electronic trading exchanges operate at a scale and speed that places extreme demands on software infrastructure. A matching engine is the central component of any exchange: it receives orders from participants, maintains an order book per instrument, and executes trades when opposing orders cross. In high-frequency trading environments, the latency between order submission and trade acknowledgement can determine profitability.
This project explores an architecture that eliminates locks on the critical path, pre-allocates all memory at startup, and uses shared memory ring buffers for trade publication, techniques commonly employed in production HFT systems.
Dependencies
C++20
Abseil
POSIX shared memory
React + NodeJs
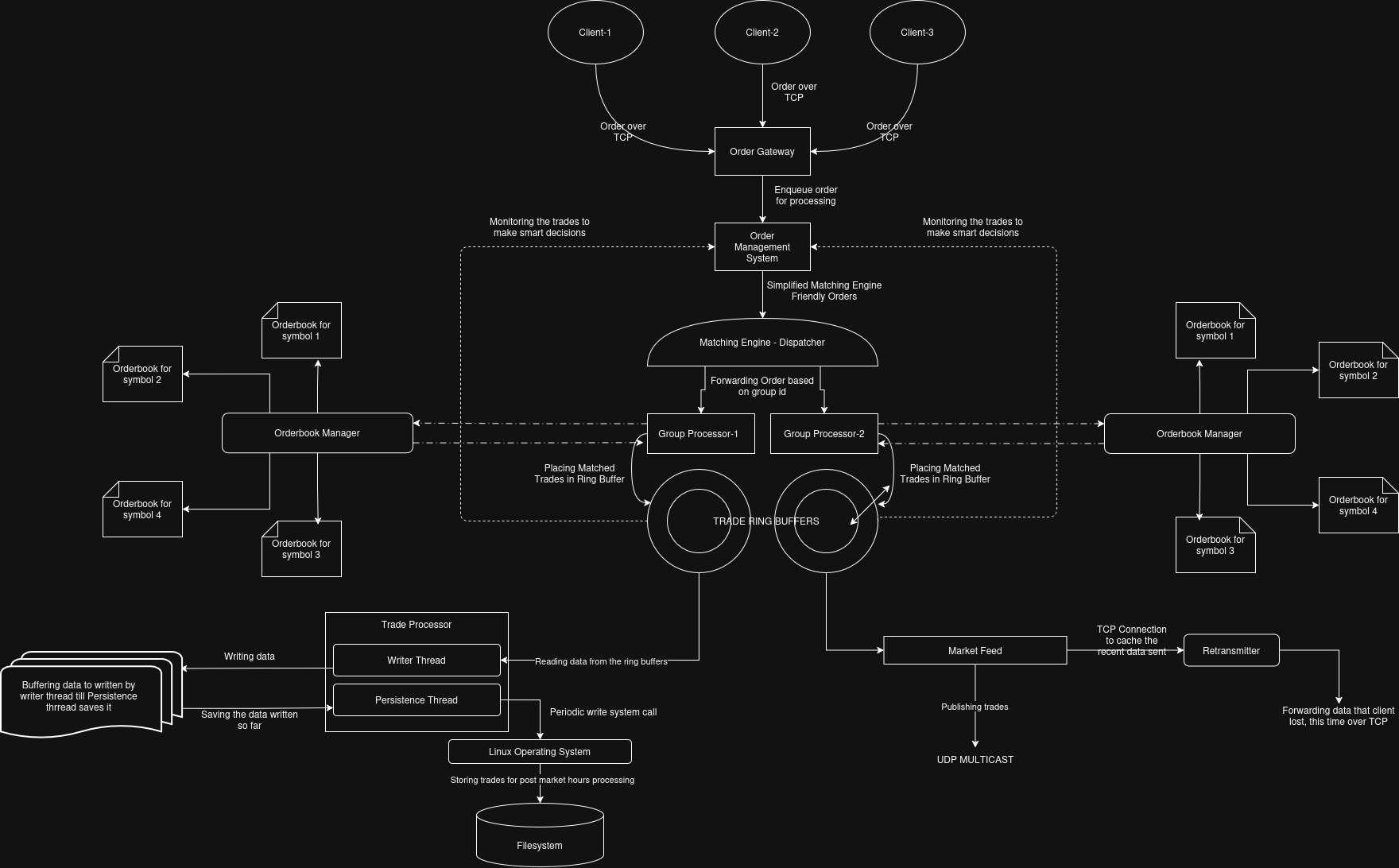
System Architecture:
TradeX follows a pipeline architecture where each stage operates independently, communicating through lock-free queues and shared-memory ring buffers. The six primary subsystems are:
- Order Gateway — accepts client TCP connections and forwards raw orders to the OMS.
- Order Management System (OMS) — validates, enriches, and classifies client orders before dispatch.
- Matching Engine Dispatcher — routes orders to the correct Group Processor by symbol group.
- Group Processors — stateful per-group matching engines maintaining their own Order Book Managers.
- Trade Ring Buffers — lock-free SPMC shared-memory ring buffers connecting producers and consumers.
- Market Feed / Retransmitter / Trade Processor — dissemination, retransmission, and persistence.
Methodology:
Order Book Design
Each symbol has a dedicated OrderBook. Price levels are stored in a flat std::vector indexed by price - lower_limit, giving O(1) access to any price level and best-price retrieval. Each price level holds a doubly-linked FIFO queue of orders backed by a custom MemPool.
Best bid and ask are tracked using two ReservablePriorityQueues (max-heap for buys, min-heap for sells). Stale entries are lazily purged when encountered at the heap top, keeping the common case O(1).
For canceling orders, a reverse mapping of order_id to location of order in memory pool is stored in a flat hash map from the abseil library.
Memory Pool
All order nodes live in a pre-allocated slab (MemPool). Allocation and deallocation are O(1) via a free-list head pointer. When a new order is added, an unused node is used from the memory pool and it is linked to the end of the link list for the respective price level. This eliminates heap fragmentation and malloc overhead in the order processing hot path.
Order Matching
Incoming buy orders are matched against the best available sell price and vice versa. Matching is a tight loop: while the incoming order has remaining quantity and a crossable price exists, the engine consumes quantity from the top of the opposing price level. Partial fills modify the resting order's quantity in-place; full fills remove it.
Trade Ring Buffer
The central IPC mechanism is a lock-free Single-Producer, Single-Consumer (SPSC) ring buffer backed by POSIX shared memory (shm_open + mmap). Each slot is an alignas(64) item_node containing the Trade payload and an atomic<uint64_t> sequence number. The protocol is:
Producer writes data to ring[index], then stores next_seq with memory_order_release. Consumer reads ring[index].seq with memory_order_acquire; if it equals next_expected_seq the slot is ready. No mutex, no CAS loop — a single atomic load per slot check.
This design achieves 4–7 ns per write operation in benchmarks, with concurrent producer-consumer latency at p50 of ~80–120 ns including shared-memory synchronisation. The goal is to ensure no jitter in performance for this part because that could lead to matching engine halting or a burst too large for consumers to handle without suffering from loss of data. The entire system is lock less and it is based on sequence numbering based logic.
Lag detection is also supported: if the producer has lapped the consumer, the consumer's expected sequence will be more than RING_SIZE behind the current slot's sequence number. The consumer can detect and report this condition without crashing.
Order Management System
The OMS runs on a single thread that handles three responsibilities in a tight loop:
• Draining the ClientOrder items from an SPSC RingBuffer and dispatching by execution type. A 4-character ticker hash provides O(1) symbol-ID lookup. The OMS also polls a shared-memory MarketState (last traded prices per symbol) to trigger stop-loss orders without a separate subscription loop.
• Polling trade ring buffers and checking if any iceberg child orders have been filled
• Scanning the shared LTP array and triggering stop-loss orders (held in max/min heaps) whose trigger price has been crossed
Market Data:UDP Multicast + TCP Retransmission
The MarketFeedReader reads from Trade Ring Buffers and packs 23 MarketDataMessages per UDP datagram using sendmmsg, amortising the per-syscall overhead by a factor of 23. A parallel TCP stream to the Retransmitter caches every message in a circular buffer indexed by sequence number.
Client Listeners detect sequence gaps and request individual messages back over a dedicated TCP connection to the Retransmitter, achieving reliable delivery without sacrificing UDP multicast throughput for the primary feed. The Retransmitter uses poll() to serve multiple clients concurrently without blocking.
Persistence: mmap + Two-Thread Pipeline
The TradeProcessor decouples writing from syncing using two threads and an SPSC queue of memory-mapped regions. The Writer Thread reads trades from the ring buffer and fills mmap regions. Once a region is full it is handed to the Persistence Thread via the SPSC queue. The Persistence Thread calls msync(MS_SYNC) and returns the region to the write pool. Neither thread blocks the matching engine.
End-of-Day Persistence
On shutdown, the OMS reads the last-traded price for each symbol from the shared MarketState and writes updated LTP and recomputed circuit limits (±10%) back to the CSV file. This allows the next session to start with accurate price limits.
Flowchart:
Results:
Benchmark Setup:
Benchmarks were run on a Linux x86-64 machine (commodity hardware) using the benchmark.cpp integration test: 900,000 AAPL limit orders (mixed buy/sell) submitted through the full OMS → Matching Engine pipeline. Latency was measured per-order inside the Group Processor thread.
| Metric | Value | Notes |
|---|---|---|
| Orders Submitted | 900000 | AAPL limit, mixed buy/sell |
| Total Enqueue time | 0.1592 s | Wall Clock |
| p10 processing latency | 26 ns | 10th percentile |
| p50 processing latency | 82 ns | Median |
| p90 processing latency | 179 ns | 90th percentile |
| p99 processing latency | 550 ns | 99th percentile |
| Trade Ring Buffer write | 4-7 ns/op | Standalone benchmark |
| Symbol Group | 2 (Configurable) | Parallel matching threads |
| Max Symbol | 2048 (Configurable) | 10-bit ID per group |
| Order Types Supported | 4 | Limit, Market, Stop-Loss, Iceberg |
Test Suite:
The Trade Ring Buffer module is covered by 30+ GoogleTest cases including:
-
Single/multi producer-consumer correctness (sequential and concurrent)
-
Lag-out detection, recovery, and storm stress tests
-
Memory ordering torture tests (2 M iterations)
-
Concurrent producer-consumer latency measurement (1 M trades, p50 / p99 reported)
-
Long-running soak test (20 M iterations)
-
Concurrent create/destroy lifecycle tests (100 iterations)
Result: All 30+ test cases pass on the development machine. The ring buffer sustains 2–5 million trades/sec in concurrent stress tests with zero data races or assertion failures.
Conclusion
The implemented system demonstrates that a functional, low-latency matching engine can be built in C++ without relying on locks, dynamic memory allocation in the hot path, or kernel-mode synchronisation primitives. The price-level array design gives O(1) order book access; the memory pool eliminates allocator overhead; and the lock-free ring buffer enables sub-microsecond trade publication between threads.
The OMS layer successfully abstracts order complexity away from the engine, handling stop-loss triggers, iceberg slicing, and symbol resolution before orders reach the matching core. The shared memory mechanism provides a lightweight channel for price updates without requiring the OMS to consume every trade in order to stay current.
Future Scope:
|
Area |
Planned Enhancement |
|---|---|
| Networking | DPDK / kernel-bypass (Solarflare OpenOnload) for real LAN deployment |
| Market Data | Level-2 order book depth feed (bids/asks per price level) |
| Symbols | Hot-add new symbols without restart; dynamic order book initialisation |
| Risk | Pre-trade risk controls — position limits, fat-finger price filters |
| Lost Message Recovery | Re-transmitters internally settling lost packets instead of asking MarketFeed for it |
| Latency | CPU pinning, isolated cores, NUMA-aware allocation for sub-100 ns p99 |
Report Information
Team Members
Team Members
Report Details
Created: April 6, 2026, 9:17 p.m.
Approved by: None
Approval date: None
Report Details
Created: April 6, 2026, 9:17 p.m.
Approved by: None
Approval date: None