

Project HYDRA - Heuristic policY Driven Recovery Agent
Abstract
Abstract
Aim
The aim of Project HYDRA is to develop a reliable and scalable system for real-time stock market monitoring and visualization, while ensuring system stability through effective monitoring and fault-tolerant mechanisms. It also focuses on implementing an intelligent reinforcement learning-based approach to enable automated scaling and self-healing, optimizing resource usage under dynamic conditions.
Introduction
Project HYDRA is inspired by the concept of Chaos Engineering, popularized by platforms like Netflix, where systems are intentionally stressed and broken to improve their resilience. Much like the mythical Hydra that grows stronger after every attack, this project focuses on building systems that learn, adapt, and recover from failures. By combining chaos testing with Reinforcement Learning (RL), HYDRA simulates real-world issues such as pod crashes, latency spikes, and resource overloads within a Kubernetes environment. An RL agent continuously observes system behavior, takes corrective actions like scaling or restarting services, and learns optimal recovery strategies over time. The goal is to create a system that not only withstands failures but evolves through them, transforming unpredictable chaos into intelligent, self-improving resilience.

Methodology
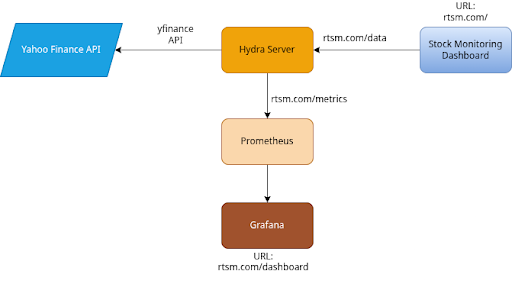
System Architecture
- Frontend (React): A user-facing dashboard that automatically polls the backend for fresh market data. It visualizes stock charts and key financial metrics (like Simple Moving Averages and volatility) while gracefully handling rate-limiting errors.
- Backend (FastAPI/Python): Serves as the core data processing engine. It fetches live data from Yahoo Finance, computes technical financial indicators, and exposes endpoints for data queries and health checks.
- Observability Stack:
- Custom Collectors: The backend includes custom Python classes (CgroupCpuCollector and CgroupMemoryCollector) that interface directly with Linux cgroups (supporting both v1 and v2) to measure raw container CPU and Memory utilization.
- Prometheus Integration: The FastAPI application registers these custom collectors alongside a histogram tracking HTTP request latency (hydra_http_request_duration_seconds) and exposes them via a dedicated /metrics endpoint.
Kubernetes Infrastructure
- Application Deployment: The Hydra backend is containerized and managed by Kubernetes with strict resource constraints (CPU/Memory limits) to ensure predictable cluster performance.
- Monitoring Integration: Prometheus is deployed with cluster-wide discovery rules to dynamically scrape application metrics, which are then visualized using a dedicated Grafana deployment.
Network Routing & Failover Strategies
- Ingress Controller: An NGINX Ingress Controller manages all incoming network traffic, routing requests seamlessly to the frontend, backend APIs, and the Grafana dashboard based on URL paths.
- High Availability: The ingress layer is configured with robust failover rules, including automatic request retries and strict timeouts, to protect against network instability or pod failures without dropping user requests.
Deployment Lifecycle
- Automation: The environment setup and deployment are fully automated via shell scripts.
- Tooling: It uses Helm to bootstrap necessary infrastructure like the NGINX Ingress and Chaos Mesh. Chaos Mesh is specifically integrated to inject intentional faults, allowing developers to test the application's automated recovery systems in a local Minikube environment.
Chaos Experiments Conducted
To evaluate the resilience and fault tolerance of the system, a series of controlled chaos experiments were conducted using Chaos Mesh. These experiments simulate real-world failure scenarios, allowing observation of system behavior under stress and validating its ability to recover and maintain service availability.
1) Pod Kill (Single & Multiple)
- Chaos Type: PodChaos
- Scenario: Pod crash, faulty or unstable deployment
- Observations:
- Pods were automatically recreated by Kubernetes, ensuring continuity.
- The service remained accessible throughout the disruption.
- Pod restart count increased, indicating recovery actions.
- A temporary spike in errors was observed during the failure window.
2) CPU Stress (90%)
- Chaos Type: StressChaos (CPU)
- Scenario: Traffic surge or inefficient processing logic
- Observations:
- CPU utilization increased to approximately 90%.
- API response latency showed a noticeable rise.
- The frontend continued to operate, albeit with slower updates.
- No system crashes or service interruptions occurred.
3) Network Delay Injection
- Chaos Type: NetworkChaos (Delay)
- Scenario: Network congestion or slow external API responses
- Observations:
- A significant increase in p95 latency was recorded.
- The frontend displayed data with visible delays.
- No request timeouts or system crashes were observed, indicating robust handling of network instability.
Reinforcement Learning
This section involves the design and implementation of an autonomous management system for cloud infrastructure using Reinforcement Learning (RL). By leveraging a custom-built simulation environment, the project demonstrates how an intelligent agent can learn to perform "self-healing" and dynamic auto-scaling in a Kubernetes-like cluster. Our primary reference for this part was based on Zhou et. al (2026) [1].
Simulation Environment Architecture
The core of the project is a custom Gymnasium-based environment named KubernetesRLEnv, which models the complexities of containerized microservices.
- Pod Simulation: Individual units, referred to as SimulatedPod, maintain internal states such as CPU load, memory usage, latency, and error rates. The simulation includes realistic failure modes where sustained high CPU load triggers memory leaks and increases latency, eventually leading to pod degradation or complete crashes.
- State Space: The agent perceives the system through a 9-dimensional observation vector. This includes the count of healthy, degraded, and crashed pods; average resource utilization metrics; and system-level metadata like the current replica count and time elapsed since the last failure.
- Action Space: The agent has four discrete control options:
- No-op: Maintaining the current state to save costs.
- Restart Pod: Attempting to recover a crashed or degraded pod.
- Scale Up: Adding new pod replicas to handle increased load.
- Scale Down: Removing replicas to optimize resource usage.
Reinforcement Learning Methodology
The project utilizes the Proximal Policy Optimization (PPO) algorithm, a state-of-the-art policy gradient method known for its stability and reliability in continuous and discrete action spaces.
- Reward Shaping: The reward function is meticulously designed to balance service availability with resource efficiency.
- Resilience: Heavy penalties are applied when pods crash, with an extreme penalty if the entire service goes offline (all pods crashed).
- Efficiency: The agent is penalized for the number of active pods to discourage over-provisioning.
- Maintenance: Small rewards are granted for maintaining an "ideal state" (all pods healthy with CPU < 70%), while specific actions like scaling up are rewarded only when the system is actually under high load.
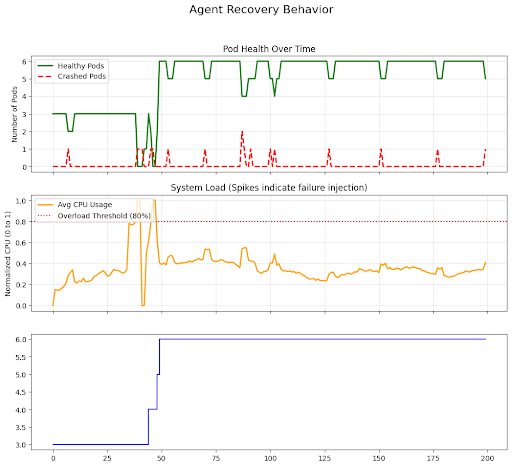
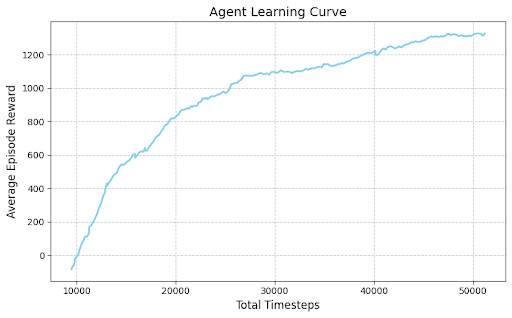
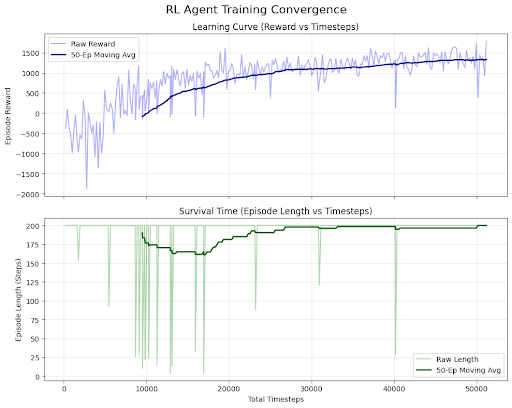
Training and Robustness
The agent was trained for 50,000 timesteps. To ensure the agent can handle real-world unpredictability, a failure injection mechanism was integrated into the training loop. This mechanism introduces random massive workload spikes (between 300% to 500% of base load) and spontaneous pod crashes. Over time, the PPO agent's mean episode reward transitioned from negative values to consistently positive scores, indicating a successful learning curve.
Results and Analysis
Evaluation of the trained model shows highly sophisticated behavior:
- Self-Healing: When the environment injects a failure, the agent quickly identifies the degraded or crashed pod and initiates a restart.
- Intelligent Auto-Scaling: Rather than scaling linearly, the agent learns to proactively scale up when average CPU utilization crosses a critical threshold (e.g., 80%) to prevent service degradation. Conversely, it scales down when the load subsides to minimize operational costs.
Visual analysis of agent behavior confirms that it prioritizes system stability, achieving high survival times and maintaining low error rates even during simulated stress periods. This implementation demonstrates that RL is a powerful tool for automating complex cloud operations that typically require manual intervention or rigid, rule-based heuristics.
Github Repository: https://github.com/IEEE-NITK/Project-HYDRA
References
[1] Zhou, H., Chan, H. Y., Zhang, S. Y., Lin, M., & Ni, J. (2026). A Kubernetes custom scheduler based on reinforcement learning for compute-intensive pods. arXiv preprint arXiv:2601.13579. https://doi.org/10.48550/arXiv.2601.13579
[3] ChaosMesh - Docs
[4] AI Meets Chaos Engineering: Designing Self-Healing Systems using Reinforcement Learning
Team
Mentors:
- Akshat Bharara
- Rudra Gandhi
- Vanshika Mittal
Mentees:
- Aadharsh Venkat
- Aniketa R
- Rohith A M
- Nischay Bharadwaj Mahesh
Report Information
Team Members
Team Members
Report Details
Created: April 21, 2026, 12:40 p.m.
Approved by: None
Approval date: None
Report Details
Created: April 21, 2026, 12:40 p.m.
Approved by: None
Approval date: None