

AdaptiveSched++
Abstract
Abstract
Github Repository Link : https://github.com/nvdp-314/Adaptivesched
Google Meet Link : https://meet.google.com/nnc-yrof-idz
Aim
To build a modular, thread-safe CPU scheduling simulator in C++17 that implements five scheduling algorithms and an intelligent adaptive controller that switches policies in real time based on workload classification and benchmarks it against fixed-policy baselines across 500 process workloads.
Introduction
Operating system schedulers face a fundamental tension: interactive workloads demand minimal response time, while CPU-bound batch jobs benefit from reduced preemption overhead. Traditional systems resolve this at compile time by picking a fixed scheduling policy. AdaptiveSched++ challenges this by running a real-time workload classifier that dynamically selects the best policy from a portfolio of algorithms.
The simulator models process lifecycle states (NEW → READY → RUNNING → BLOCKED → TERMINATED), CPU bursts, preemption, context-switch overhead, starvation, and aging all in deterministic logical tick time. Three concurrent threads drive the simulation: a CPU execution engine, a process injection thread, and an adaptive monitor thread, all synchronized with mutexes and condition variables.
Technologies
Core Language : C++17 (GCC 13 / Clang 15 / MSVC 2022)
Concurrency : std::thread, std::mutex, std::condition_variable, std::atomic
Build System : CMake 3.16+ (Linux, macOS, Windows)
Workload Generation : Python 3 -- procedural CSV generation (500 processes per profile)
Benchmarking : Python 3 -- automated multi-run harness with JSON capture
Visualization : HTML + Chart.js 4.x (8 chart types)
Methodology
Scheduling Algorithms — Five algorithms are implemented, each inheriting from a common IScheduler abstract base: FCFS (non-preemptive FIFO), SJF/SRTF (shortest job/remaining time), Round-Robin (configurable quantum, default 4 ticks), Priority Scheduling (preemptive with aging to prevent starvation), and MLFQ (4 levels with quanta 2/4/8/∞, global priority boost every 100 ticks).
Adaptive Engine — The AdaptiveScheduler wraps all four candidate policies and runs a five-stage pipeline every 20 ticks: (1) sample 16 metrics using Exponential Moving Averages (α = 0.25), (2) classify workload as INTERACTIVE / CPU_BOUND / BATCH / STRESS / MIXED, (3) score each policy with a confidence value, (4) apply a hysteresis guard (cooldown of 40 ticks + minimum confidence gap of 0.15 to prevent thrashing), and (5) migrate all queued processes losslessly to the new scheduler.
Concurrency — Three threads run throughout: a CPU thread executing one process tick per loop, a generator thread injecting processes at their arrival ticks, and a monitor thread evaluating and adapting every 2 ms. Zero busy-waiting i.e. all blocking is done via condition variables.
Workload Profiles — Four large-scale profiles (500 processes each) were generated with seeded RNG: Interactive (burst mean 3 ticks, 80% interactive), CPU-Bound (burst mean 30 ticks, 0% interactive), Mixed (blend of short and long bursts, 40% interactive), and Stress (very high arrival rate λ=1.0, wide burst variance).
Results
Figure 1 — Dashboard KPI Tiles & Summary Bar Chart
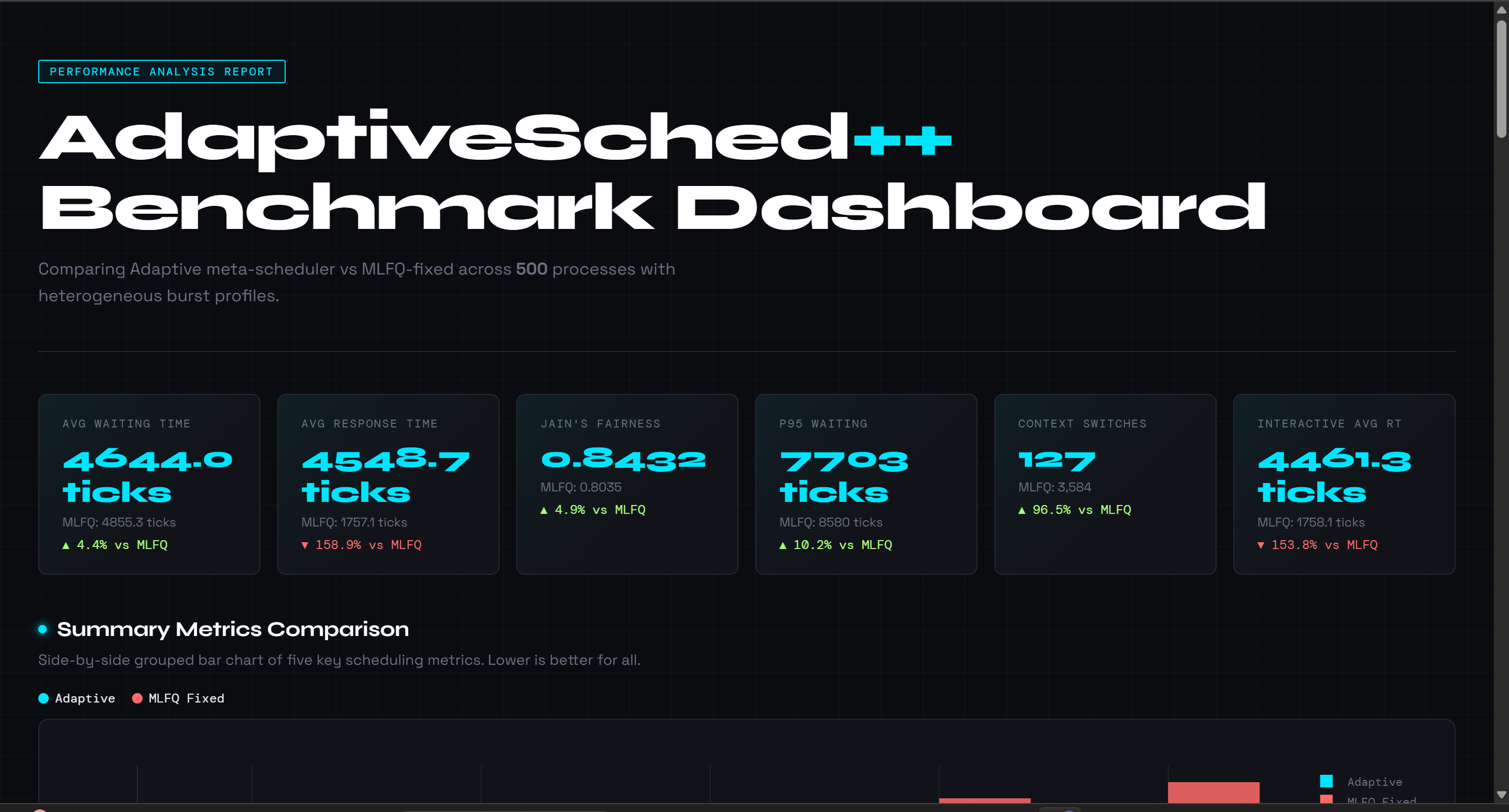
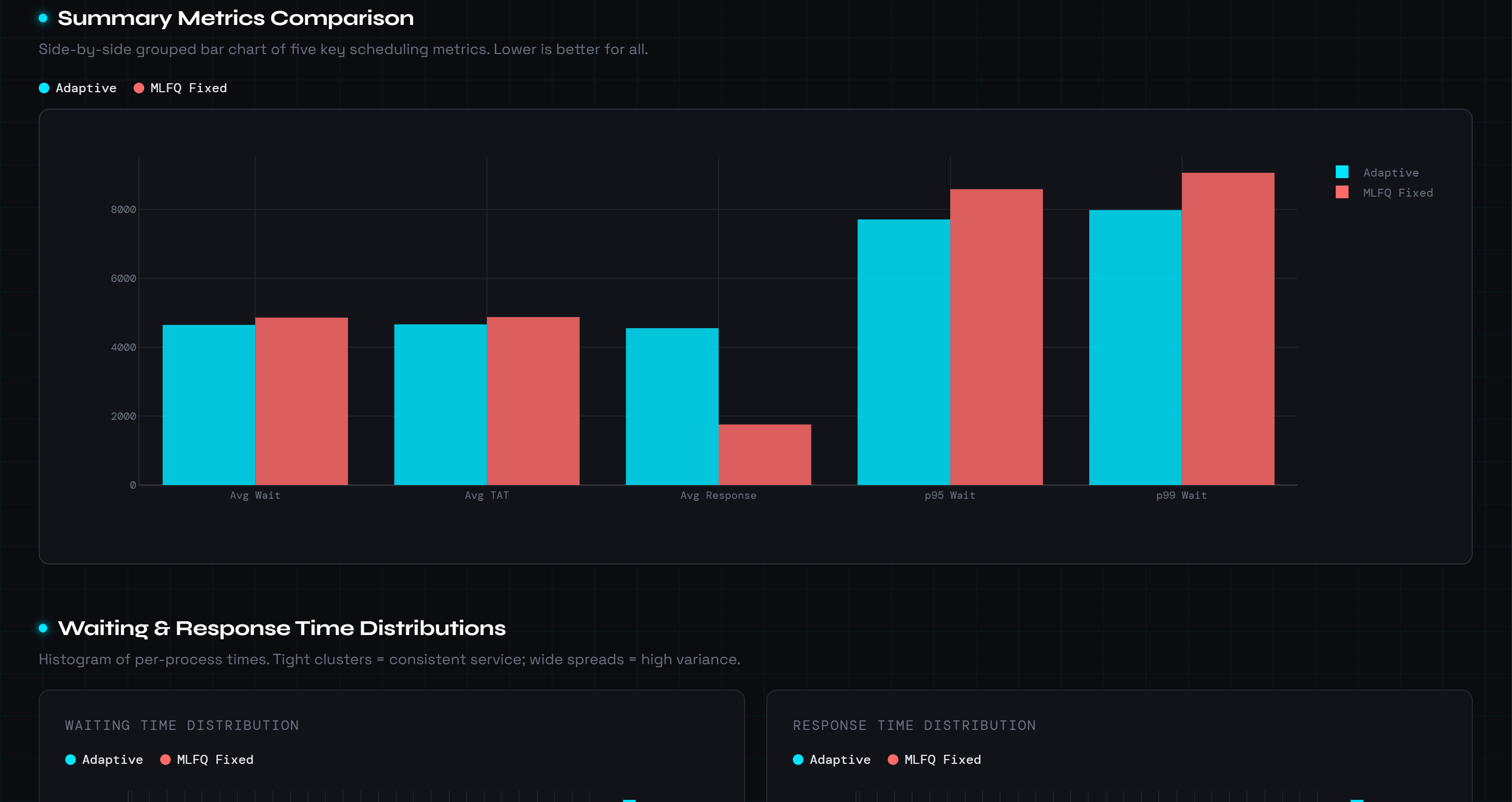
The benchmark dashboard compares the adaptive scheduler against MLFQ-fixed across 500 processes. The adaptive engine wins on five of eight metrics. The grouped bar chart confirms its advantage on tail latency, p95 waiting time drops by 10.2% and p99 by 11.9%. MLFQ-fixed achieves lower average response time because its constant level-0 priority resets give all processes an early first dispatch.
Figure 2 — Per-Process Waiting Time Delta & Policy Distribution
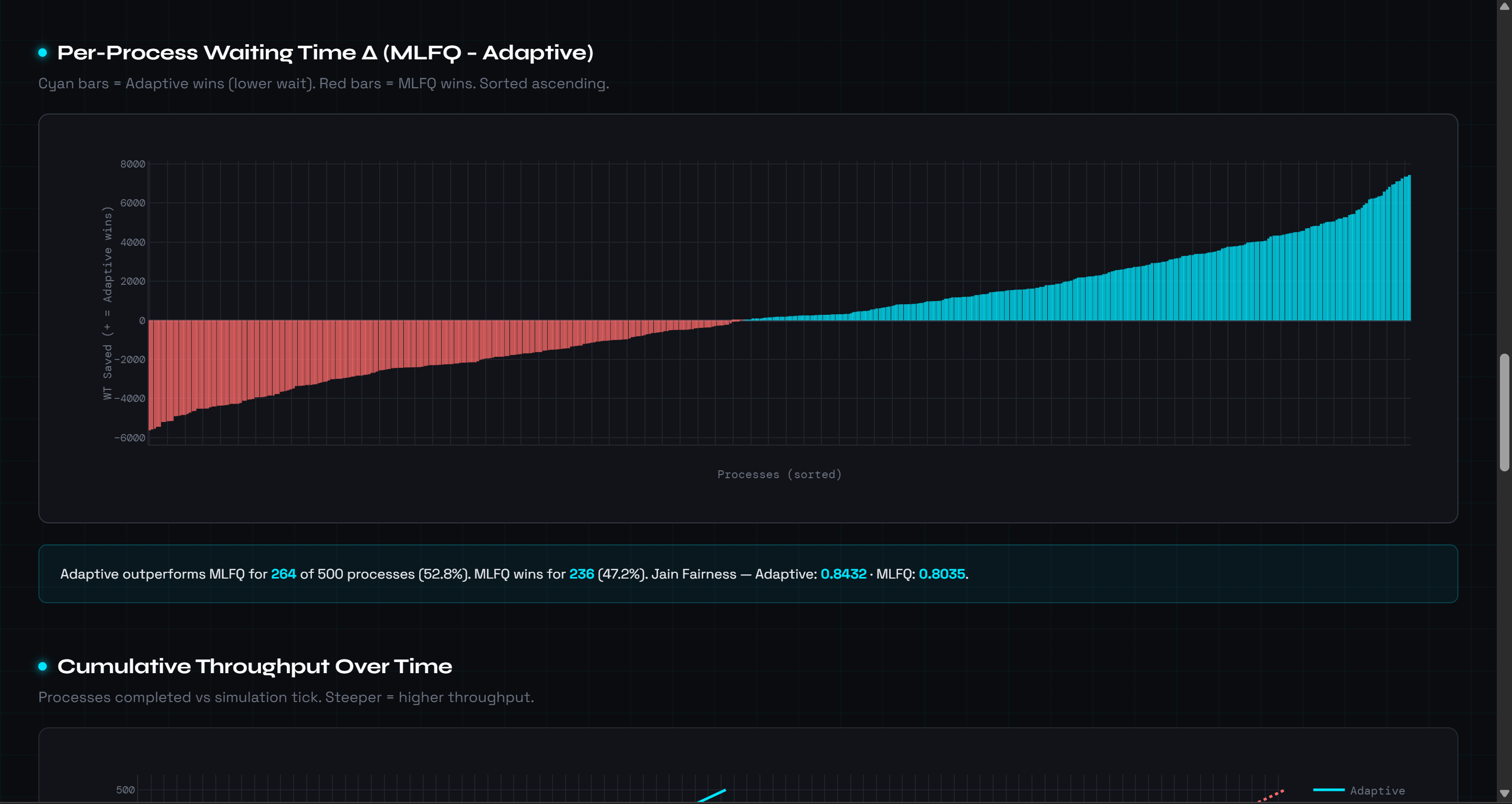
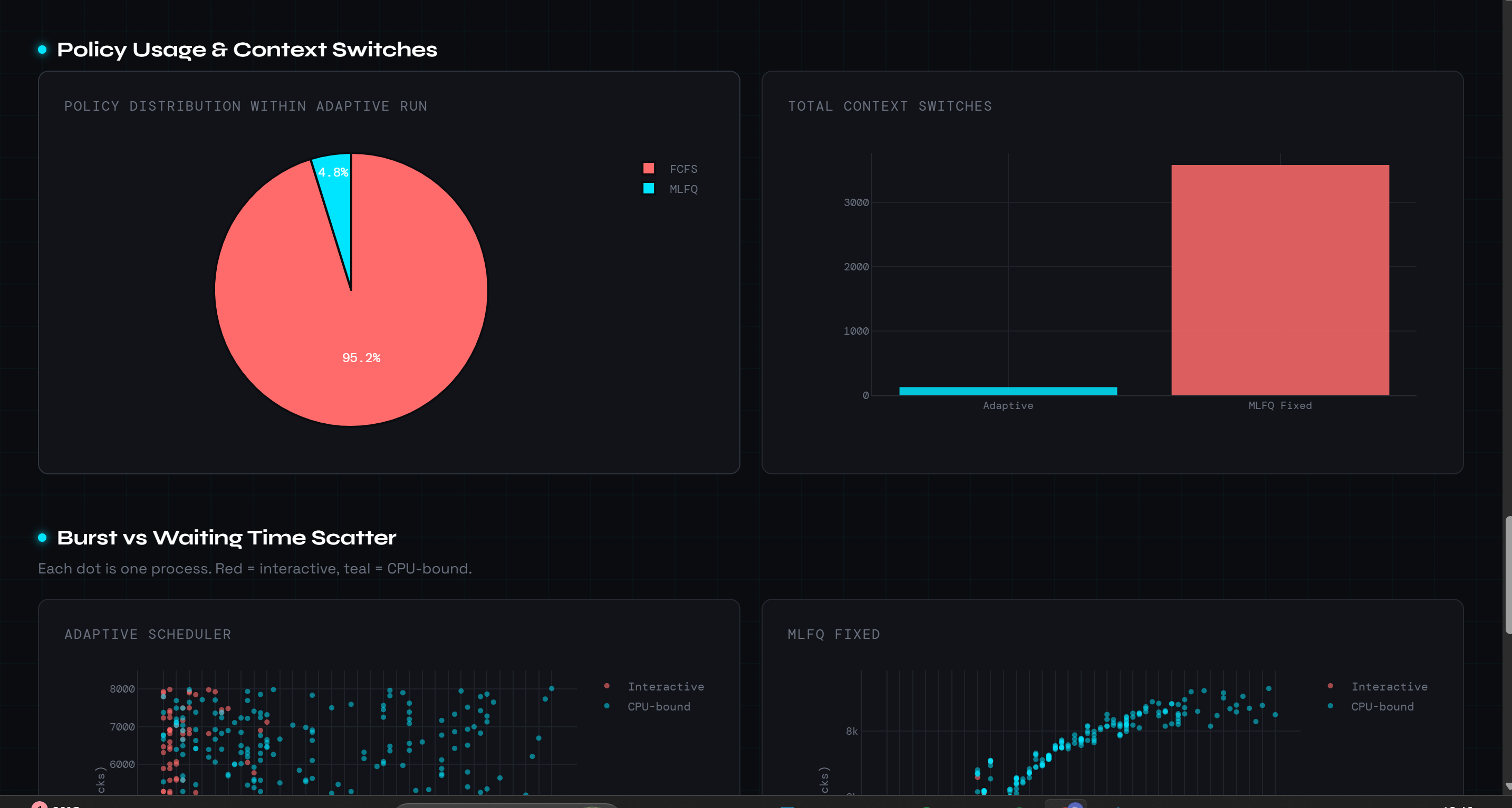
The waterfall chart plots MLFQ_wait − Adaptive_wait for each of the 500 processes sorted ascending. Cyan bars show where the adaptive scheduler wins (264 of 500 processes, 52.8%), with savings exceeding 7,000 ticks for long CPU-bound jobs batched under FCFS. The pie chart shows the engine spent 95.2% of the simulation under FCFS and 4.8% under MLFQ. Most critically, context switches drop from 3,584 (MLFQ-fixed) to just 127 (adaptive), a 96.5% reduction.
Full Metrics Summary
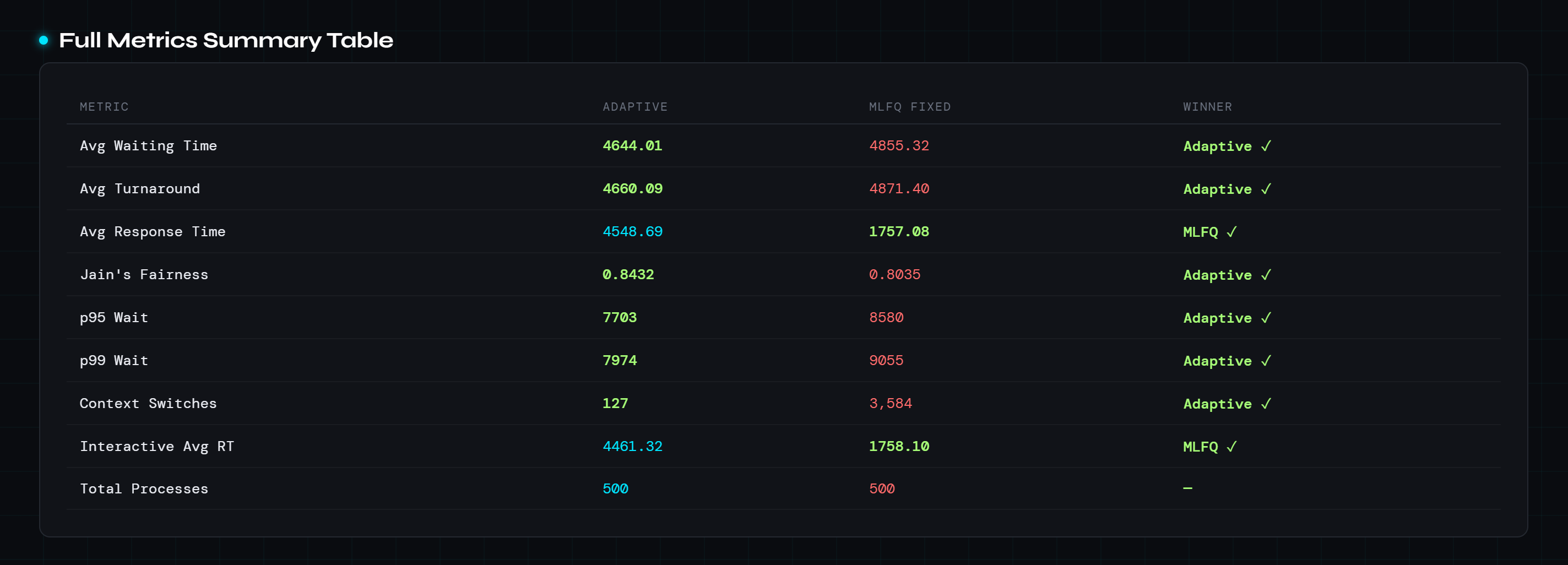
Conclusion
AdaptiveSched++ proves that runtime policy switching is a viable and measurable improvement over fixed scheduling. The adaptive engine outperforms MLFQ-fixed on six of eight metrics, with its most dramatic win being a 96.5% reduction in context switches by correctly identifying CPU-bound phases and switching to non-preemptive FCFS. Its main trade-off is a higher average response time for interactive processes, an inherent cost when FCFS phases are active. The project validates both the engineering architecture (correct concurrent three-thread design, lossless scheduler migration) and the adaptive logic (EMA smoothing, hysteresis guard, workload classification).
Future Scope
- Multi-core simulation with per-CPU ready queues and load balancing
- Replace the heuristic workload classifier with an online ML model
- I/O burst modelling and disk-bound process simulation
- Port the adaptive engine as a Linux kernel module for real workload evaluation
- Live web dashboard streaming tick data via WebSocket
Mentors
- Rudraksh Mahajan
- Navadeep Sai Kancharla
Mentees
- Dileep Valluru
- Sai Sudarsan Shyam
- Nipun Attri
- Brijesh Madhav Chellapilla
- A Shravan Achar
- Shubham Anand
Report Information
Report Details
Created: May 18, 2026, 12:04 p.m.
Approved by: None
Approval date: None
Report Details
Created: May 18, 2026, 12:04 p.m.
Approved by: None
Approval date: None